Hello guys, if you want to learn about character encoding, particularly UTF-18 and UTF-16, and looking for a good resource then you have come to the right place. In this article, I am going to discuss 10 important points about UTF-8 and UTF-16 character encoding which I believe every programmer should learn. This is one of the fundamental topics to which many programmers don't pay attention unless they face issues related to character encoding. Knowing how a character is stored and how they are represented in such a way what computer can understand is very important in this age of globalization and internationalization where you need to store and work through data that contains characters from multiple languages.
Since data is stored as bytes in computers, you also need to know you can convert bytes to characters and how does character encoding plays an important role when you convert bytes to characters. In my career as a Java programmer, I have faced many issues related to character encoding like relying on default character encoding of the platform, etc.
I have also blogged about default character encoding in the past as well shared my thoughts on the difference between UTF-8, UTF-16, and UTF-32 character encoding. This article is actually the next step as in this article, we will deep dive into UTF-8 and UTF-16 character encoding and learn more about it.
By the way, this topic is not just important for any Java programmer but for any Software developer coding in Python, C++, JavaScript, or any other programming language. This is one of the fundamental topics for Software developers, and I strongly believe every programmer should know about it.
10 Points about UTF-8 and UTF-16 Character Encoding
Here are some important points about Unicode, UTF-8, and UTF-16 character encoding to revise or build your knowledge about character encoding, how characters are stored, and how to convert bytes to the character in your computer program.
You should remember there are many more character encodings available but we have only focused on UTF-8 and UTF-16 in this article as they are the most fundamental after ASCII, which many of you already know.
1. Character Set
Unicode is a character set, which defines code points to represent almost every single character in the world, including characters from languages, currency symbols, and special characters. Unicode uses numbers to represent these characters, known as code points. Encoding is a way to represent them in memory or store it in a disk for transfer and persistence.
UTF-8, UTF-16, and UTF-32 are three different ways to encode Unicode code points. Here 8, 16, and 32 represent how many bits they use, but that's not the complete truth, which we will see in the next point.
2. How many Bytes it Takes
There is a lot of misconception about UTF-8 encoding among software developers like UTF-8 always takes 1 byte to represent a character. This is not true, UTF-8 is variable-length encoding and it can take anywhere from 1 to 4 bytes.
In fact in UTF-8, every code point from 0-127 is stored in a single byte. On the other hand, UTF-16 can be either take 2 or 4 bytes, remember not 3 bytes. UTF-32 encoding has a fixed length and always takes 4 bytes.

3. Unicode Characters
There is another misconception I have seen among programmers is that since UTF-8 cannot represent every single Unicode character that's why we need bigger encodings like UTF-16 and UTF-32, well, that's completely wrong. UTF-8 can represent every character in the Unicode character set.
The same is true for UTF-16 and UTF-32, the difference comes from the fact that how they represent like the UTF-8 mostly takes 1 byte but can take more than 1, UTF-16 either takes 2 or 4 bytes, but it also suffers from endianness.
4. Backward Compatible
UTF-8 is the most backward-compatible character encoding, the original goal of it to generate the same bytes for ASCII characters. It can be passed through many tools intended for ASCII only, of course with few exceptions e.g. including avoiding composed Latin glyphs.
5. Endianness problems
UTF-8 also avoids endianness problems. It does not suffer from endianness issues like UTF-16 does, in fact, it was designed to avoid the complications of endianness and byte order marks in UTF-16, which uses a couple of bytes at the start of the text, known as byte order marks (BOM) to represent endianness e.g. big-endian or little-endian. BOM is encoded at U+FEFF byte order mark (BOM). BOM use is optional, and, if used, should appear at the start of the text stream.
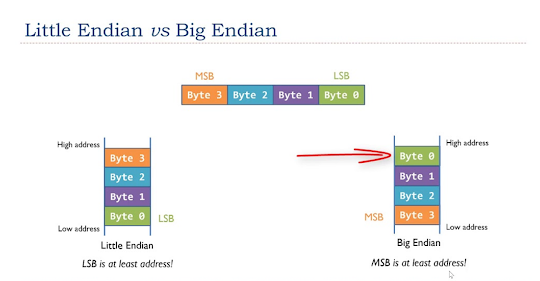
6. Standard
UTF-8 is the de-facto encoding for Most Mac and Linux C APIs, Java uses UTF-16, JavaScript also uses UTF-16. It is also a favorite encoding of the Internet, if you do a right-click and view-source of a web page, you will most likely see Content-Type: text/plain; charset="UTF-8" or.
The Internet Mail Consortium (IMC) also recommends that all e-mail programs be able to display and create mail using UTF-8. UTF-8 is also increasingly being used as the default character encoding in operating systems, programming languages, and various APIs.
7. Non English letters
When you see a bunch of question marks in your String, think twice, you might be using the wrong encoding. There are lots of popular encoding which can only store some code points correctly and change all the other code points into question marks. For example, Windows-1252 and ISO-8859-1 are two popular encodings for English text, but if you try to store Russian or Hebrew letters in these encodings, you will see a bunch of question marks.
8. Space
UTF-8 is very space-efficient. It generally ends up using fewer bytes to represent the same string than UTF-16, unless you're using certain characters a lot (like for European languages), on the other hand, UTF-32 always uses 4 bytes, so it takes more space to represent the same String.

9. Codepoints
UTF-8 encodes each of the 1,112,064 code points from the Unicode character set using one to four 8-bit bytes (a group of 8 bits is known as an "octet" in the Unicode Standard). Code points with lower numerical values i.e. earlier code positions in the Unicode character set, which tend to occur more frequently are encoded using fewer bytes.
The first 128 characters of Unicode, which correspond one-to-one with ASCII, are encoded using a single octet with the same binary value as ASCII, making valid ASCII text valid UTF-8-encoded Unicode as well.
That's all about things every programmer should know about UTF-8 and UTF-16 encoding. Character encoding is one of the fundamental topics which every programmer should study and having a good knowledge of how characters are represented and how they are stored is essential to create global applications which can work in multiple languages and can store data from around the world.
That's all about things every programmer should know about UTF-8 and UTF-16 encoding. Character encoding is one of the fundamental topics which every programmer should study and having a good knowledge of how characters are represented and how they are stored is essential to create global applications which can work in multiple languages and can store data from around the world.
Other Java Articles you may like to explore:
- 10 Advanced Spring Boot Courses for Java Programmers
- 10 Tools Every Java Developer Learn in 2023
- Top 5 Courses to learn Spring Boot in 2023
- The 2023 Java Developer RoadMap
- 10 Free courses to learn Maven, Jenkins, and Docker for Java developers
- 10 Books Java Developers Should Read in 2023
- 10 Programming languages to Learn in 2023
- Why Java Developers learn Docker in 2023
- 20 Libraries Java developer should know
- My favorite free courses to learn Java in depth
- Top 5 courses to learn Spring Framework in Depth
- 10 Scala and Groovy Frameworks to learn in 2023
- 10 Free Spring Boot Courses for Java developers
- 10 Frameworks Java and Web Developer Should learn in 2023
No comments:
Post a Comment