
Hello guys, if you are preparing for technical interviews for Software Engineering job then you may be aware of the importance of Software Design or System design topic.
It is one of the most important but at the same time very tough topic to master and many programmers even experienced developer struggle to solve System design problems during interview, particularly while interviewing with top tech companies like Google, Meta, Amazon, Apple, Microsoft, Netflix etc, popularly known as FAANG.
If you are also preparing for programming job interview and looking for best System design and Software design resources then you are at the right place.
Earlier, I have shared best System Design Books, System Design Questions, System Design Cheat Sheets, and best Places to learn System Design and in this article, I am going to share best System Design Interview courses from Udemy, one of my favorite place to learn programming and technical stuff.
A couple of years ago, you can hardly find any decent System design course online like on Udemy, the ones which are available hardly touch the topic which matters like scalability, resiliency, and flexibility but things have changed since.
Nowadays there are so many System design courses you can find on Udemy but again not everything is great and you need to be careful while choosing the right course for you.
A lot of my readers asked me about which System design course to join on Udemy to prepare for programming interviews so I decided to share my recommendations.
The list includes System design interview courses from those who have been part of those interview and has experience from both side of table, as a candidate and interviewer. For example, Frank Kane, whose System Design interview course is one of the best on Udemy is an ex Amazon hiring manager.
You can join one or more of these System design courses to prepare well for your System design interview. O
ne of the best thing about Udemy is that its very affordable and now is probably the best time as they are running the biggest sale of the season where all the top courses are available for almost 85% discount and you can join a couple of nice courses with a price of one.
Anyway, let’s jump into best System design courses form Udemy, ByteByteGo, DesignGurus.io, ZTM Academy, Educative, Codemia.io, InterviewReddy.io, and other popular online platform and find which one is right for you.
10 Best Courses to Learn Software Design and System Design in 2026
Without wasting anymore of your time, here is a list of best online courses you can join on Udemy to learn about essential System design concepts and prepare for System design interviews in 2026.
As I said these courses have been created by System design experts and people who have cracked FAANG interviews and worked on those companies like Amazon, Facebook, Google etc.
So you will be learning from the best and also get a first hand experience about which System design topic to prepare to do well on your System design interviews.
1. ByteByteGo System Design Course by Alex Xu
Not many people know about this resource but its one of the best resource I come across to learn and improve both System Design and Software Design.
This site is created by Alex Wu, author of famous System Design Interview — An insider’s guide, one of the best selling System Design book on Amazon and it not just cover book’s content but more than that.
The best thing about this site is that it not only provide step by step solution of common System Design Problem but also explains many key concepts in an unique illustrative way.
You will also learn about Scalability like How to scale your web app From Zero To Millions Of Users, Messaging, Caching and other key system design concepts. If you are serious about System design, then I highly recommend you to checkout this site.
Here is the link to learn more — ByteByteGo
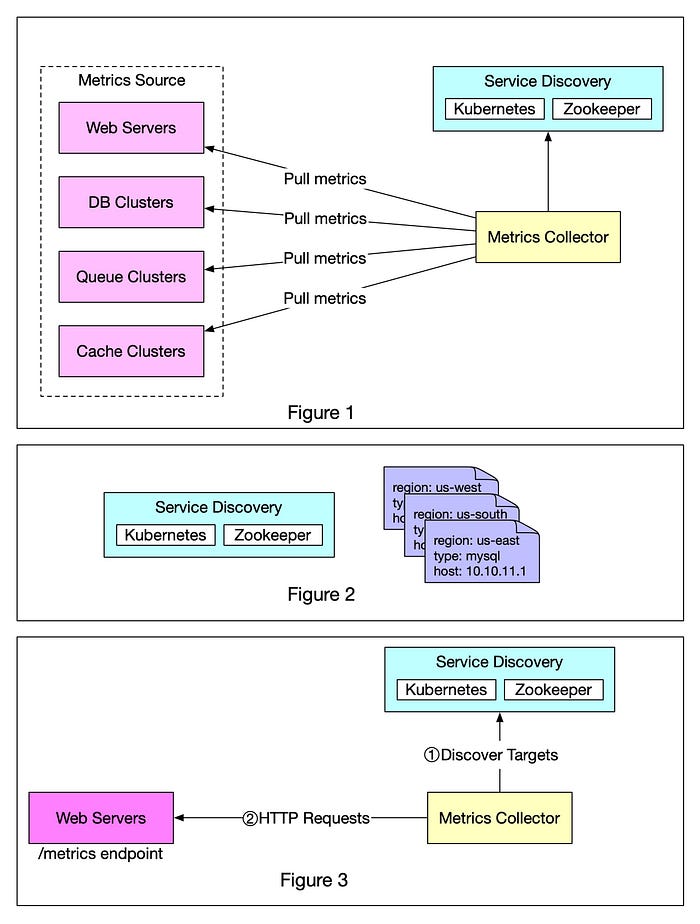
You can see how easy it is to understand concept using this kind of illustrative diagram and ByteByteGo is full of such diagrams. it also has many free content like how to design YouTube and WhatsApp as well as nice a Framework For System Design Interviews.
2. Codemia.io
While this not exactly a System design course, its a great platform to practice System design problems for interviews. You will find more than 120+ System design problems like designing URL shortner, Twitter, TicketMaster, Vending Machine and much more.
Unlike any other platform, Codemia.io provides a comprehensive framework and structure to answer System design problems starting from requirement, back of envelop estimation, high level design, low level design and much more.
Coming back to system design problems, while few problems are free, most of them are paid but you can get access to all of them for just $69 (30% discount now, original price $99)
Here is the link to learn more — Join Codemia.io for discount

In short, one of the best place to level up your System design skills in 2026.
3. Mastering the System Design Interview by Frank Kane
In this course, you will learn everything about designing a system that scale, often known as Google’s scale to handle millions and billions of users and transactions as well as Algorithms and Data Structures like Bloom Filter which plays a critical role in large scale system.
The course will also teach you System design strategies which can be crucial even if you don’t know the answer.
Apart from System design essentials, this 5 hour long course will also give you insider tips for your system design interview from a former Amazon hiring manager as well as 6 mock interviews for practice!
If cost is your concern and if you are looking for an affordable course to prepare for your System Design interview, then this is the best Software design course for you
Here is the link to join this course — Mastering the System Design Interview

4. Grokking Modern System Design For Software Engineers (Educative.io)
This is one of the newest System design course on Educative and this reflect all the hard work and experience they gained by created a couple of best System design courses you will find online.
As System design best practices have evolved the expertise required to design and build these systems have evolved and that’s where this course will help you.
It share most modern and up-to-date System design best practices you will find online.
This course starts with teaching you first the fundamental building blocks. From there, you will learn u how to combine those building blocks to design and deploy scalable services through real-world examples.
After completing this course, you will have the skills to build novel solutions to the most complex problems in modern software engineering.
Here are key things you will learn in this best System design course
- 16 fundamental building blocks of modern system design (like Blob Store, Key Value Store, etc.)
- Learn and apply the RESHADED approach to system design
- Unpack (and be able to design) some of the world’s most innovative scalable systems (including YouTube, WhatsApp, Uber, and Twitter)
- Apply that design mastery to create novel solutions for emerging problems by creating your own distributed systems
- Learn how to take on the system design interview and level up your career, and
No matter where your career takes you, system design will remain a cornerstone of modern software engineering. Team managers and product managers will architect scalable solutions, leveraging big data stores, user interaction, and distributed microservices.
Meanwhile, developers will implement those designs by linking the building blocks together. System design isn’t going anywhere, so everyone in the world of software engineering needs to develop a working knowledge of system design.
Here is the link to join this course — Grokking Modern System Design For Software Engineers
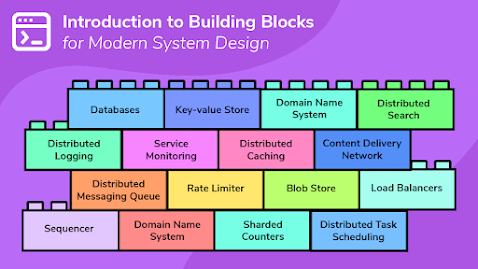
The course will act as a great brief introduction to the amazing world of modern system design. It is perfect for beginners as you will learn about system design from absolute scratch. You will learn exactly what system design is and why is it used.
By the way, you can either join this course individually or you can take an Educative Unlimited subscription (recommended) to get access to their 300+ high quality, text-based, interactive courses to learn key skills for coding interviews, software development, and technology.
5. Grokking the System Design Interview on DesignGuru
This is one of my favorite System design course which was earlier available on Educative but now it's moved exclusively on Designguru.io.
This site is created by
, a former software engineer @ Facebook, Microsoft, Hulu and writer, and probably one of the best person to learn System design concepts.This course not only give you solution of popular System design questions like how to design a chat system like WhatsApp? or how to design a URL shortener but also a complete System Design template on how to approach and solve a system design problem.
Apart from that its an interactive online course where you can practice online right on your browser and it also got community support, but the best thing I liked about this course is the real case studies on various system design problems That’s the real gem of this course.
In short, its one of the best course to learn system design and if you want to crack your system design interview with confidence, you should checkout this course. Here is a also a nice system deign template or cheat sheet you can checkout from them
Here is the link to join this course — Grokking the System Design Interview
They also offer bundle of all of their system design and coding interview courses where you can get them for big discount. Just use code GURU to get 30% discount on any DesignGurus.io membership or course.
6. System Design Interview Course by Exponent
I didn’t know about this website for a long time but when I found I was like OMG, how can I miss this one!! It truly one of the best website to go if you are preparing for FAANG interviews.
They have helped many people succeed in Amazon and Microsoft PM, TPM, and Software Development Engineer role and they have specialized courses for Amazon, Facebook, and Google.
You will learn to answer challenging system design questions like Design Twitter, Instagram, Parking lot, design a Web Crawler, and many other popular Software design questions. Overall a perfect System design course for engineers, managers, and architects.
But apart from the course they also provide mock interviews which is like real drill as well 1-to-1 coaching and interactive discussion on popular interview questions from Google, Facebook, Microsoft and Amazon, and you can join them for just $12 a month now (70% discount).
If you are preparing for System design interviews on FAANG companies then I highly recommend this course and website to you.
Here is the link to join — System Design Interview Course by Exponent

7. Rocking System Design by Rajdeep Saha [Udemy Course]
This is another system design course you can join on Udemy to learn about System design and Software design in general. This course is created by Cloud Architect Rajdeep Saha.
In this course, you will learn how to solve any system design problem by mastering the basics like scaling, sharding, hashing, microservices, load balancers, security, well architected framework, and more.
You will also learn about how to answer system design interview questions which is an important skill if you are serious about cracking System Design Interview of FAANG companies.
The best thing about this course is that it will also teaches you AWS implementation of the design using Kubernetes, Lambda, API Gateway, EC2, ALB, NLB etc.
The course also covers important topics about software architecture like pros/cons of different design decisions, bad vs. good answer, pitfalls to avoid, and more.
It also contains many quizzes to test your knowledge with up-to-date system design quizzes. Overall a nice course to learn about System Design and Software architecture in 2026.
Here is the link to join this course — Rocking System Design
8. System Design Interview Guide for Software Architecture
This is another amazing System design course which is created by Facebook engineer Sandeep Kaul. This 8 hour long course covers a lot of essential System design topics as well as solution of common System design problems like how to design Facebook and how to design Instagram etc.
Here are the common System design questions which are explained in this Udemy course:
1. URL shortener design
2. AirBnb Booking System design
3. Amazon System Design
4. How to design WhatsApp
5. Uber System Design
6. Twitter System Design
7. How to design YouTube
8. How to design Zoom
9. How to design Google Map
10.How to design a notification system like Netflix
The best thing about this course is the different case studies it share which can be used to learn how to design modern system which can scale as well run 24x7 all the time. I highly recommend this course to anyone who is preparing for System Design Interview.
Here is the link to join this course — System Design Interview Guide
9. Pragmatic System Design by Alexey Soshin
If you are looking for a to-the-point course which covers all key System design topics like Concurrency, Scalability, SQL vs NoSQL, Microservices etc then this Udemy course is the perfect course for you.
It also teach you how to solve most popular FANG interview questions like Yelp Design, Netflix Design, and Amazon System design questions.
Here are key topics you will learn in this course:
- Scalability concepts
- Common communication protocols
- Caching and Redis
- Concurrency
- Database design and PostgreSQL
- Sharding strategies
Even if you are not preparing for Technical interviews, you can join this course to improve your knowledge about System design and Software architecture in general. I highly recommend this course to e senior engineers who want to learn about system design.
Here is the link to join this course — Pragmatic System Design
10. Software Architecture & Technology of Large-Scale Systems
This one is another Software architecture course on Udemy which is worth checking out. It’s one of the most comprehensive System design course with more than 25.5 hours of content while other course only provides content of 5 to 8 hours.
It also covers key system design topics like how to create Software Systems with High Performance, Scalability, Availability, Security using Modern Technologies.
The course start with a basic three tier application architecture then move along with advanced and modern software architecture like Microservices and distributed system.
You will also learn how to cater Non-Functional Requirements like How to design architecture considering Performance, Scalability, Reliability, and Security.
Here is the link to join this course — Software Architecture & Technology of Large-Scale Systems
You will also get exposure of highly scalable technology and tech stack like Nodejs, Redis, Cassandra, Kafka, Hadoop, Elasticsearch etc. More importantly you will learn how to use Docker and Kubernetes for large scale production deployment, a key skill in this era of cloud computing.
11. ZTM Academy’s System Design Interview Course
This is one of the most recent and up-to-date course on System Design, created by team of ZTM Academy and Yihua, one of their lead instructor and System design expert.
What I liked about this course is their chapter on scalability where they explained the difference between horizontal and vertical scaling of Systems as well as challenges faced by distributed systems.
What sets this course apart from other system design courses is its emphasis on seeing the bigger picture and executing on it.
It goes beyond low-level coding and encourages students to understand the broader system they are a part of, fostering a deeper comprehension of the “why” behind their work.
By providing a problem-solving framework and practical knowledge gained from Yihua’s industry experience, the course empowers students to become better problem solvers and programmers.
Here is the link to join this course — Master the Coding Interview: System Design + Architecture

Btw, you would need a ZTM membership to watch this course which costs around $39 per month but also provides access to many super engaging and useful courses like this Python course. You can also use my code FRIENDS10 to get a 10% discount on any subscription you choose.
That’s all about the best Software Design and System Design Interview course for programmers and developers in 2026. To be honest these are the top resources and its hard to leave anyone out but considering the time I recommend you to join only one or two of these courses as price is not a problem.
If you like to learn from multiple resources then you can also join all of them but make sure you use them judicially as you will not have enough time to go through every course. I generally make one course as corner stone and the keep referring others to solidify different topics.
If I connect to one instructor better than I stick with that course more because when you connect to the instructor you tend to learn better, faster and in-depth.
You can also watch previews of these courses to see if you are connecting with instructor before joining these courses to save your time and money.
If you cannot withstand previews then you won’t enjoy the course either. So make sure you watch the preview System design lesson to see if the course deserve your time and money.
Other System Design Interview Resources you may like
- How to Prepare for System Design Interview in 2026
- Is DesignGuru’s System Design Course worth it?
- 10 best System Design Courses for Programmers
- 5 Websites to learn Data Structure and Algorithms for FREE
- 5 Websites to learn SQL Online for FREE
- Top 5 Java Frameworks to Learn in 2026
- 21 Websites to Learn Coding Online for FREE
- Is Grokking the System Design Interview Course worth it?
- The Complete DevOps Engineer RoadMap
- 50+ Data Structure Interview Questions for Programmers
- Is ByteByteGo really worth it for System design
- 10 Free System Design Course for Programmers
Thanks for reading this article so far. If you like these best System design and Software Design Interview Courses from Udemy and Educative then please share them with your friends and colleagues. If you have any questions or feedback then please drop a note.
P. S. — If you are looking for a free online course to learn System Design and Software design then I also suggest you to checkout this Case Studies for System Design Interviews free course on Udemy by Erdem. This 2-hour free course is great resource to prepare for System design interviews in 2026.











