Converting a byte array to String seems easy but what is difficult is, doing it correctly. Many programmers make the mistake of ignoring character encoding whenever bytes are converted into a String or char or vice versa. As a programmer, we all know that computer's only understand binary data i.e. 0 and 1. All things we see and use like images, text files, movies, or any other multi-media are stored in form of bytes, but what is more important is the process of encoding or decoding bytes to a character. Data conversion is an important topic in any programming interview, and because of the trickiness of character encoding, this question is one of the most popular String Interview questions on Java Interviews.
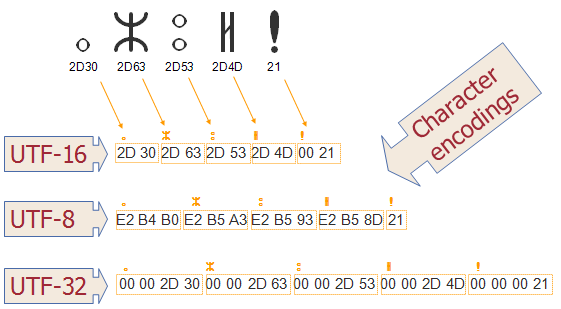
While reading a String from input sources like XML files, HTTP requests, network port, or database, you must pay attention to which character encoding (e.g. UTF-8, UTF-16, and ISO 8859-1) they are encoded. If you will not use the same character encoding while converting bytes to String, you would end up with a corrupt String that may contain totally incorrect values.
You might have seen ?, square brackets after converting byte[] to String, those are because of values your current character encoding is not supporting and just showing some garbage values.
I tried to understand why programs make character encoding mistakes more often than not, and my little research and own experience suggests that it may be because of two reasons, first not dealing enough with internationalization and character encodings and second because ASCII characters are supported by almost all popular encoding schemes and have same values.
Since we mostly deal with encoding like UTF-8, Cp1252, and Windows-1252, which displays ASCII characters (mostly alphabets and numbers) without fail, even if you use different encoding schemes.
The real issue comes when your text contains special characters e.g. 'é', which is often used in French names. If your platform's character encoding doesn't recognize that character then either you will see a different character or something garbage, and sadly until you got your hands burned, you are unlikely to be careful with character encoding.
In Java, things are a little bit more tricky because many IO classes like InputStreamReader by default use the platform's character encoding. What this means is that, if you run your program in different machines, you will likely get different outputs because of the different character encoding used on that machine.
While reading a String from input sources like XML files, HTTP requests, network port, or database, you must pay attention to which character encoding (e.g. UTF-8, UTF-16, and ISO 8859-1) they are encoded. If you will not use the same character encoding while converting bytes to String, you would end up with a corrupt String that may contain totally incorrect values.
You might have seen ?, square brackets after converting byte[] to String, those are because of values your current character encoding is not supporting and just showing some garbage values.
I tried to understand why programs make character encoding mistakes more often than not, and my little research and own experience suggests that it may be because of two reasons, first not dealing enough with internationalization and character encodings and second because ASCII characters are supported by almost all popular encoding schemes and have same values.
Since we mostly deal with encoding like UTF-8, Cp1252, and Windows-1252, which displays ASCII characters (mostly alphabets and numbers) without fail, even if you use different encoding schemes.
The real issue comes when your text contains special characters e.g. 'é', which is often used in French names. If your platform's character encoding doesn't recognize that character then either you will see a different character or something garbage, and sadly until you got your hands burned, you are unlikely to be careful with character encoding.
In Java, things are a little bit more tricky because many IO classes like InputStreamReader by default use the platform's character encoding. What this means is that, if you run your program in different machines, you will likely get different outputs because of the different character encoding used on that machine.
In this article, we will learn how to convert byte[] to String in Java both by using JDK API and with the help of Guava and Apache commons.
You should always use a later one, don't rely on platform encoding. I know, it could be the same or you might not have faced any problem so far, but it's better to be safe than sorry. As I pointed out in my last post about printing byte array as Hex String,
It's also one of the best practices to specify character encoding while converting bytes to the character in any programming language. It might be possible that your byte array contains non-printable ASCII characters. Let's first see JDK's way of converting byte[] to String :
1) You can use the constructor of String, which takes a byte array and character encoding
This is the right way to convert bytes to String, provided you know for sure that bytes are encoded in the character encoding you are using.
2) If you are reading byte array from any text file e.g. XML document, HTML file, or binary file, you can use the Apache Commons IO library to convert the FileInputStream to a String directly. This method also buffers the input internally, so there is no need to use another BufferedInputStream.
In order to correctly convert those byte arrays into String, you must first discover correct character encoding by reading metadata like Content-Type, <?xml encoding="…">, etc, depending on the format/protocol of the data you are reading. This is one of the reasons I recommend using XML parsers like SAX or DOM parsers to read XML files, they take care of character encoding by themselves.
Some programmers, also recommend using Charset over String for specifying character encoding, e.g. instead of "UTF-8" use StandardCharsets.UTF_8 mainly to avoid UnsupportedEncodingException in the worst case.
There are six standard Charset implementations guaranteed to be supported by all Java platform implementations. You can use them instead of specifying the encoding scheme in String. In short, always prefer StandardCharsets.ISO_8859_1 over "ISO_8859_1", as shown below :
Other standard charsets supported by Java platform are :
If you are reading bytes from the input stream, you can also check my earlier post about 5 ways to convert InputStream to String in Java for details.
And, this is what happens when you convert a byte array to String without specifying the character encoding, e.g. :
This will use the platform's default character encoding, which is Cp1252 in this case, because we are running this program in Eclipse IDE. You can see that letter 'é' is not displayed correctly.
To fix this, specify character encoding while creating String from byte array, e.g.
By the way, let me make it clear that even though I have read XML files using InputStream here it's not a good practice, in fact, it's a bad practice. You should always use proper XML parsers for reading XML documents. If you don't know how, please check this tutorial. Since this example is mostly to show you why character encoding matters, I have chosen an example that was easily available and looks more practical.
How to convert byte[] to String in Java? Example
There are multiple ways to change byte array to String in Java, you can either use methods from JDK, or you can use open-source complementary APIs like Apache commons and Google Guava. These API provides at least two sets of methods to create String from byte array; one, which uses default platform encoding, and the other which takes character encoding.You should always use a later one, don't rely on platform encoding. I know, it could be the same or you might not have faced any problem so far, but it's better to be safe than sorry. As I pointed out in my last post about printing byte array as Hex String,
It's also one of the best practices to specify character encoding while converting bytes to the character in any programming language. It might be possible that your byte array contains non-printable ASCII characters. Let's first see JDK's way of converting byte[] to String :
1) You can use the constructor of String, which takes a byte array and character encoding
String str = new String(bytes, "UTF-8");
This is the right way to convert bytes to String, provided you know for sure that bytes are encoded in the character encoding you are using.
2) If you are reading byte array from any text file e.g. XML document, HTML file, or binary file, you can use the Apache Commons IO library to convert the FileInputStream to a String directly. This method also buffers the input internally, so there is no need to use another BufferedInputStream.
String fromStream = IOUtils.toString(fileInputStream, "UTF-8");
In order to correctly convert those byte arrays into String, you must first discover correct character encoding by reading metadata like Content-Type, <?xml encoding="…">, etc, depending on the format/protocol of the data you are reading. This is one of the reasons I recommend using XML parsers like SAX or DOM parsers to read XML files, they take care of character encoding by themselves.
There are six standard Charset implementations guaranteed to be supported by all Java platform implementations. You can use them instead of specifying the encoding scheme in String. In short, always prefer StandardCharsets.ISO_8859_1 over "ISO_8859_1", as shown below :
String str = IOUtils.toString(fis,StandardCharsets.UTF_8);
Other standard charsets supported by Java platform are :
- StandardCharsets.ISO_8859_1
- StandardCharsets.US_ASCII
- StandardCharsets.UTF_16
- StandardCharsets.UTF_16BE
- StandardCharsets.UTF_16LE
If you are reading bytes from the input stream, you can also check my earlier post about 5 ways to convert InputStream to String in Java for details.
Original XML
Here is our sample XML snippet to demonstrate issues with using default character encoding. This file contains the letter 'é', which is not correctly displayed in Eclipse because its default character encoding is Cp1252.xml version="1.0" encoding="UTF-8"?>
<banks>
<bank>
<name>Industrial & Commercial Bank of China </name>
<headquarters> Beijing , China</headquarters>
</bank>
<bank>
<name>Crédit Agricole SA</name>
<headquarters>Montrouge, France</headquarters>
</bank>
<bank>
<name>Société Générale</name>
<headquarters>Paris, Île-de-France, France</headquarters>
</bank>
</banks>
And, this is what happens when you convert a byte array to String without specifying the character encoding, e.g. :
String str = new String(filedata);
This will use the platform's default character encoding, which is Cp1252 in this case, because we are running this program in Eclipse IDE. You can see that letter 'é' is not displayed correctly.
xml version="1.0" encoding="UTF-8"?>
<banks>
<bank>
<name>Industrial & Commercial Bank of China </name>
<headquarters> Beijing , China</headquarters>
</bank>
<bank>
<name>Crédit Agricole SA</name>
<headquarters>Montrouge, France</headquarters>
</bank>
<bank>
<name>Société Générale</name>
<headquarters>Paris, ÃŽle-de-France, France</headquarters>
</bank>
</banks>
To fix this, specify character encoding while creating String from byte array, e.g.
String str = new String(filedata, "UTF-8");
By the way, let me make it clear that even though I have read XML files using InputStream here it's not a good practice, in fact, it's a bad practice. You should always use proper XML parsers for reading XML documents. If you don't know how, please check this tutorial. Since this example is mostly to show you why character encoding matters, I have chosen an example that was easily available and looks more practical.
Java Program to Convert Byte array to String in Java
Here is our sample program to show why relying on default character encoding is a bad idea and why you must use character encoding while converting byte array to String in Java. In this program, we are using Apache Commons IOUtils class to directly read files into a byte array.It takes care of the opening/closing input stream, so you don't need to worry about leaking file descriptors. Now how you create String using that array, is the key. If you provide the right character encoding, you will get the correct output otherwise a nearly correct but incorrect output.
import java.io.FileInputStream; import java.io.IOException; import org.apache.commons.io.IOUtils; /** * Java Program to convert byte array to String. * In this example, we have first * read an XML file with character encoding "UTF-8" into byte array * and then created * String from that. When you don't specify a character encoding, Java uses * platform's default encoding, which may not be the same if file is * a XML document coming from another system, emails, * or plain text files fetched from an * HTTP server etc. * You must first discover correct character encoding * and then use them while converting byte array to String. * * @author Javin Paul */ public class ByteArrayToString{ public static void main(String args[]) throws IOException { System.out.println("Platform Encoding : " + System.getProperty("file.encoding")); FileInputStream fis = new FileInputStream("info.xml"); // Using Apache Commons IOUtils to read file into byte array byte[] filedata = IOUtils.toByteArray(fis); String str = new String(filedata, "UTF-8"); System.out.println(str); } } Output : Platform Encoding : Cp1252 <?xml version="1.0" encoding="UTF-8"?> <banks> <bank> <name>Industrial & Commercial Bank of China </name> <headquarters> Beijing , China</headquarters> </bank> <bank> <name>Crédit Agricole SA</name> <headquarters>Montrouge, France</headquarters> </bank> <bank> <name>Société Générale</name> <headquarters>Paris, Île-de-France, France</headquarters> </bank> </banks>
Things to remember and Best Practices
Always remember, using character encoding while converting byte array to String is not a best practice but a mandatory thing. You should always use it irrespective of the programming language. By the way, you can take note of the following things, which will help you to avoid a couple of nasty issues :- Use character encoding from the source e.g. Content-Type in HTML files, or <?xml encoding="…">.
- Use XML parsers to parse XML files instead of finding character encoding and reading it via InputStream, some things are best left for demo code only.
- Prefer Charset constants e.g. StandardCharsets.UTF_16 instead of String "UTF-16"
- Never rely on the platform's default encoding scheme
These rules should also be applied when you convert character data to byte e.g. converting String to a byte array using String.getBytes() method. In this case, it will use the platform's default character encoding, instead of this, you should use the overloaded version which takes character encoding.
That's all on how to convert byte array to String in Java. As you can see that Java API, particularly java.lang.String class provides methods and constructor that takes a byte[] and returns a String (or vice versa), but by default they rely on the platform's character encoding, which may not be correct, if the byte array is created from XML files, HTTP request data or from network protocols. You should always get the right encoding from the source itself. If you like to read more about what every programmer should know about String, you can check out this article.











2 comments :
Never encodings. Decide which encoding you are going to use, and always explicitly specify it in all conversions between strings and bytes and bytes and strings. I recommend UTF-8. UTF-16 is a variable length encoding that nearly pretends to be a fixed width encoding. In short, always remember following tips while dealing with byte array and String
- Don't use String(bytes), Instead use new String(bytes, encoding).
- Never use String.getBytes(), Instead use string.getBytes(encoding).
- Avoid using new InputStreamReader(inputStream), rather use new InputStreamReader(inputStream, encoding).
- Never use new OutputStreamWriter(outputStream), Instead use new OutputStreamWriter(outputStream, encoding).
this list can go on and on, while passing byte array, also check the API if an overloaded method exists which also takes encoding, find it and use that.
Static code analyzers such as FindBugs and PMD can help find instances here the character encoding was not specified properly.
Post a Comment