Hello guys, if you are looking for an answer of popular Java interview question, how HashMap works in Java? or How HashMap works internally in Java then you have come to the right place. In this article, I will not just answer those question but also many related questions like How get() and put() method works in Java? what role equals() and hashcode() play in HashMap, How HashMap resize itself, and why key object of HashMap should be Immutable in Java. Let's start with the basics first. HashMap in Java works on hashing principles. It is a data structure that allows us to store object and retrieve it in constant time O(1) provided we know the key. Also this is one of my most popular article with more than 6 million views and I have now updated it to include latest information like how HashMap now uses a balanced tree instead of linked list for storing collision objects and new diagrams on HashMap working which provide visual explanations.
In hashing, hash functions are used to link keys and values in HashMap. Objects are stored by the calling put(key, value) method of HashMap and retrieved by calling the get(key) method.
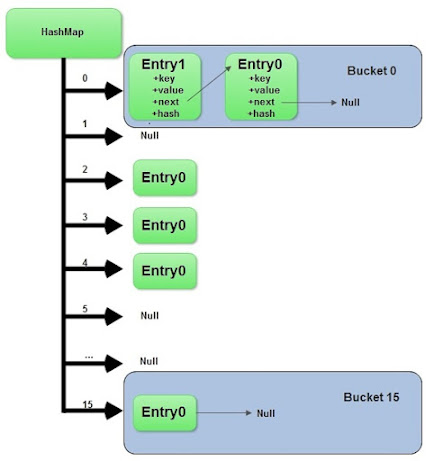
When we call the put method, the hashcode() method of the key object is called so that the hash function of the map can find a bucket location to store the value object, which is actually an index of the internal array, known as the table.
HashMap internally stores mapping in the form of Map.Entry object which contains both key and value object.
When you want to retrieve the object, you call the get() method and again pass the key object. This time again key objects generate the same hash code (it's mandatory for it to do so to retrieve the object and that's why HashMap keys should be immutable e.g. String) and we end up at the same bucket location.
When you want to retrieve the object, you call the get() method and again pass the key object. This time again key objects generate the same hash code (it's mandatory for it to do so to retrieve the object and that's why HashMap keys should be immutable e.g. String) and we end up at the same bucket location.
If there is only one object then it is returned and that's your value object which you have stored earlier.
Things get a little tricky when collisions occur. It's easy to answer this question if you have read a good book or course on data structure and algorithms like these data structure courses and books. If you know how the hash table data structure works then this is a piece of cake.
Since the internal array of HashMap is of fixed size, and if you keep storing objects, at some point in time hash function will return the same bucket location for two different keys, this is called collision in HashMap. In this case, a linked list is formed at that bucket location and a new entry is stored as the next node.
If we try to retrieve an object from this linked list, we need an extra check to search for the correct value, this is done by the equals() method. Since each node contains an entry, HashMap keeps comparing the entry's key object with the passed key using equals() and when it returns true, Map returns the corresponding value.
Things get a little tricky when collisions occur. It's easy to answer this question if you have read a good book or course on data structure and algorithms like these data structure courses and books. If you know how the hash table data structure works then this is a piece of cake.
Since the internal array of HashMap is of fixed size, and if you keep storing objects, at some point in time hash function will return the same bucket location for two different keys, this is called collision in HashMap. In this case, a linked list is formed at that bucket location and a new entry is stored as the next node.
If we try to retrieve an object from this linked list, we need an extra check to search for the correct value, this is done by the equals() method. Since each node contains an entry, HashMap keeps comparing the entry's key object with the passed key using equals() and when it returns true, Map returns the corresponding value.
Since searching inlined list is an O(n) operation, in the worst case hash collision reduces a map to a linked list. This issue is recently addressed in Java 8 by replacing the linked list with a balanced tree using hashcode to search in O(logN) time.
By the way, you can easily verify how HashMap works by looking at the code of HashMap.java in your Eclipse IDE if you know how to attach the source code of JDK in Eclipse.
Interview questions start with a simple statement:

If candidate fails to recognize this and say it only stores Value in the bucket they will fail to explain the retrieving logic of any object stored in Java HashMap.

 The interviewee will say we will call the get() method and then HashMap will use Key Object's hashcode to find out bucket location and retrieves the Value object but then you need to remind him that there are two Value objects which are stored in the same bucket, so they will say about traversal in LinkedList until we find the value object.
The interviewee will say we will call the get() method and then HashMap will use Key Object's hashcode to find out bucket location and retrieves the Value object but then you need to remind him that there are two Value objects which are stored in the same bucket, so they will say about traversal in LinkedList until we find the value object.
.jpg)
Now if you clear this entire Java HashMap interview, You will be surprised by this very interesting question "What happens On HashMap in Java if the size of the HashMap exceeds a given threshold defined by load factor ?".
10. How null key is handled in HashMap? Since equals() and hashCode() are used to store and retrieve values, how does it work in the case of the null key?
The null key is handled specially in HashMap, there are two separate methods for that putForNullKey(V value) and getForNullKey(). Later is an offloaded version of get() to look up null keys.
How HashMap Internally Works in Java?
How HashMap works in Java or sometimes how does get method works in HashMap is a very common question on Java interviews nowadays.
Almost everybody who worked in Java knows about HashMap, where to use HashMap, and the difference between Hashtable and HashMap then why did this interview question become so special? Because of the depth, it offers.
It has become a very popular Java interview question in almost any senior or mid-senior level Java interview. Investment banks mostly prefer to ask this question and sometimes even ask you to implement your own HashMap based upon your coding aptitude.
The introduction of ConcurrentHashMap and other concurrent collections has also made these questions a starting point to delve into a more advanced feature. let's start the journey.
It has become a very popular Java interview question in almost any senior or mid-senior level Java interview. Investment banks mostly prefer to ask this question and sometimes even ask you to implement your own HashMap based upon your coding aptitude.
The introduction of ConcurrentHashMap and other concurrent collections has also made these questions a starting point to delve into a more advanced feature. let's start the journey.
Interview questions start with a simple statement:
1. Have you used HashMap before or What is HashMap? Why do you use it?
Almost everybody answers this with yes and then the interviewee keeps talking about common facts about HashMap like HashMap accepts null while Hashtable doesn't, HashMap is not synchronized, HashMap is fast, and so on along with basics like its stores key and value pairs, etc.
This shows that the person has used HashMap and is quite familiar with the functionality it offers, but the interview takes a sharp turn from here and the next set of follow-up questions gets more detailed about the fundamentals involved with HashMap in Java. Interviewer strike back with questions like:
2. Do you Know how HashMap works in Java or How does get () method of HashMap works in Java
And then you get answers like, I don't bother its standard Java API, you better look code on Java source or Open JDK; I can find it out in Google at any time, etc.
But some interviewee definitely answers this and will say HashMap works on the principle of hashing, we have put(key, value) and get(key) method for storing and retrieving Objects from HashMap.
When we pass Key and Value object to put() method on Java HashMap, HashMap implementation calls hashCode method on Key object and applies returned hashcode into its own hashing function to find a bucket location for storing Entry object, the important point to mention is that HashMap in Java stores both key and value object as Map.Entry in a bucket is essential to understand the retrieving logic.
Here is also a nice flowchart diagram which shows how does get() method of HashMap or Hashtable works in Java and how does it retrieve value:
If candidate fails to recognize this and say it only stores Value in the bucket they will fail to explain the retrieving logic of any object stored in Java HashMap.
Though, this answer is very much acceptable and does make sense that the interviewee has a fair bit of knowledge on how hashing works and how HashMap works in Java.
But this is just the start of the story and confusion increases when you put the candidate on scenarios faced by Java developers on day by day basis. The next question could be about collision detection and collision resolution in Java HashMap like:
3. What will happen if two different objects have the same hashcode?
Now from here onwards real confusion starts, sometime candidate will say that since hashcode is equal, both objects are equal and HashMap will throw an exception or not store them again, etc, Then you might want to remind them about equals() and hashCode() contract that two unequal objects in Java can have the same hashcode.
Some will give up at this point and few will move ahead and say "Since hashcode is same, bucket location would be same and collision will occur in HashMap Since HashMap uses LinkedList to store object, this entry (object of Map.Entry comprise key and value ) will be stored in LinkedList.
Great !! this answer makes sense though there are many collision resolution methods available like linear probing and chaining, this is the simplest, and HashMap in Java does follow this. But the story does not end here and the interviewer asks further questions
Btw, here is a nice flowchart diagram which shows what will happen if two different objects hashcode() method will return same value while storing in HashMap
4. How will you retrieve the Value object if two Keys will have the same hashcode?
At that point you can ask how do you identify value object because you don't have value object to compare until they know that HashMap stores both Key and Value in LinkedList node or as Map.Entry they won't be able to resolve this issue and will try and fail.
But those bunch of people who remember this key information will say that after finding bucket location, we will call keys.equals() method to identify a correct node in LinkedList and return associated value object for that key in Java HashMap. Perfect this is the correct answer.
In many cases, interviewee fails at this stage because they get confused between hashCode() and equals() or keys and values object in Java HashMap which is pretty obvious because they are dealing with the hashcode() in all previous questions and equals() come in the picture only in case of retrieving value object from HashMap in Java.
Good and experienced Java developer will point out here that using an immutable, final object with proper equals() and hashcode() implementation would act as perfect Java HashMap keys and improve the performance of Java HashMap by reducing collision.
Immutability also allows caching their hashcode of different keys which makes the overall retrieval process very fast and suggests that String and various wrapper classes e.g. Integer very good keys in Java HashMap.
Now if you clear this entire Java HashMap interview, You will be surprised by this very interesting question "What happens On HashMap in Java if the size of the HashMap exceeds a given threshold defined by load factor ?".
Until you know how HashMap works exactly you won't be able to answer this question. If the size of the Map exceeds a given threshold defined by load-factor e.g. if the load factor is .75 it will act to re-size the map once it filled 75%.
Similar to other collection classes like ArrayList, Java HashMap re-size itself by creating a new bucket array of size twice the previous size of HashMap and then start putting every old element into that new bucket array. This process is called rehashing because it also applies the hash function to find a new bucket location.
If you manage to answer this question on HashMap in Java you will be greeted by "do you see any problem with resizing of HashMap in Java", you might not be able to pick the context, and then he will try to give you a hint about multiple threads accessing the Java HashMap and potentially looking for race condition on HashMap in Java.
So the answer is Yes there is a potential race condition that exists while resizing HashMap in Java, if two thread at the same time found that now HashMap needs resizing and they both try to resize.
On the process of resizing HashMap in Java, the element in the bucket which is stored in the linked list get reversed in order during their migration to the new bucket because Java HashMap doesn't append the new element at the tail instead it append new element at the head to avoid tail traversing.
If race condition happens then you will end up with an infinite loop. Though this point, you can potentially argue that what the hell makes you think to use HashMap in a multi-threaded environment to interviewer :)
Other Popular Hashtable and HashMap Questions
Here are few Java HashMap interview questions which is contributed by readers of the Javarevisited blog and I have included them on main article for everyone's benefit.
5. Why String, Integer, and other wrapper classes are considered good keys?
String, Integer, and other wrapper classes are natural candidates of the HashMap key, and String is the most frequently used key as well because String is immutable and final, and overrides equals and hashcode() method. Other wrapper class also shares similar property.
Immutability is required, in order to prevent changes on fields used to calculate hashCode() because if a key object returns different hashCode during insertion and retrieval then it won't be possible to get an object from HashMap.
Immutability is best as it offers other advantages as well like thread-safety, If you can keep your hashCode the same by only making certain fields final, then you go for that as well.
Immutability is best as it offers other advantages as well like thread-safety, If you can keep your hashCode the same by only making certain fields final, then you go for that as well.
Since the equals() and hashCode() method is used during retrieval of value objects from HashMap, it's important that key objects correctly override these methods and follow contact.
If an unequal object returns different hashcode then the chances of collision will be less which subsequently improves the performance of HashMap.
6. Can we use any custom object as a key in HashMap?
This is an extension of previous questions. Of course, you can use any Object as a key in Java HashMap provided it follows equals and hashCode contract and its hashCode should not vary once the object is inserted into Map.
If the custom object is Immutable then this will be already taken care of because you can not change it once created.
7. Can we use ConcurrentHashMap in place of Hashtable?
This is another question which getting popular due to the increasing popularity of ConcurrentHashMap. Since we know Hashtable is synchronized ConcurrentHashMap provides better concurrency by only locking a portion of the map determined by concurrency level.
ConcurrentHashMap is certainly introduced as Hashtable and can be used in place of it, but Hashtable provides stronger thread-safety than ConcurrentHashMap. See my post difference between Hashtable and ConcurrentHashMap for more details.
Personally, I like this question because of its depth and the number of concepts it touches indirectly if you look at questions asked during the interview this HashMap question has verified
- The concept of hashing
- Collision resolution in HashMap
- Use of equals () and hashCode () and their importance in HashMap?
- The benefit of the immutable object?
- Race condition on HashMap in Java
- Resizing of Java HashMap
Just to summarize here are the answers which do make sense for the above questions
8. How does HashMap work in Java?
HashMap works on the principle of hashing, we have put() and get() method for storing and retrieving objects from HashMap.
When we pass both key and value to put() method to store on HashMap, it uses key object hashcode() method to calculate hashcode and them by applying hashing on that hashcode it identifies bucket location for storing value object.
While retrieving it uses the key object equals method to find out the correct key-value pair and return the value object associated with that key. HashMap uses a linked list in case of collision and objects will be stored in the next node of the linked list.
Also, HashMap stores both key and value tuples in every node of the linked list in the form of Map.Entry object.
9. What will happen if two different HashMap key objects have the same hashcode?
They will be stored in the same bucket but no next node of the linked list. And keys equals () method will be used to identify the correct key-value pair in HashMap.
10. How null key is handled in HashMap? Since equals() and hashCode() are used to store and retrieve values, how does it work in the case of the null key?
The null key is handled specially in HashMap, there are two separate methods for that putForNullKey(V value) and getForNullKey(). Later is an offloaded version of get() to look up null keys.
Null keys always map to index 0.
This null case is split out into separate methods for the sake of performance in the two most commonly used operations (get and put), but incorporated with conditionals in others. In short, the equals() and hashcode() methods are not used in the case of null keys in HashMap.
here is how nulls are retrieved from HashMap
private V getForNullKey() {
This null case is split out into separate methods for the sake of performance in the two most commonly used operations (get and put), but incorporated with conditionals in others. In short, the equals() and hashcode() methods are not used in the case of null keys in HashMap.
here is how nulls are retrieved from HashMap
private V getForNullKey() {
if (size == 0) { return null; } for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; }
In terms of usage, Java HashMap is very versatile and I have mostly used HashMap as a cache in an electronic trading application I have worked on.
Since the finance domain used Java heavily and due to performance reasons we need caching HashMap and ConcurrentHashMap comes as very handy there.
After some research, the Java team found that most of these Map are temporary and never use that many elements, and only end up wasting memory. Also, From JDK 1.8 onwards HashMap has introduced an improved strategy to deal with a high collision rate.
Since a poor hash function e.g. which always return the location of the same bucket, can turn a HashMap into a linked list, like converting the get() method to perform in O(n) instead of O(1) and someone can take advantage of this fact, Java now internally replace linked list to a binary true once a certain threshold is breached.
If you prefer to watch than read then I have also explained this concept of HashMap internal working on our YouTube channel where we have talked about the internal working of HashMap and How HashMap works in general.
HashMap Changes in JDK 1.7 and JDK 1.8
There is some performance improvement done on HashMap and ArrayList from JDK 1.7, which reduces memory consumption. Due to this empty Maps are lazily initialized and will cost you less memory. Earlier, when you create HashMap like new HashMap() it automatically creates an array of default length e.g. 16.After some research, the Java team found that most of these Map are temporary and never use that many elements, and only end up wasting memory. Also, From JDK 1.8 onwards HashMap has introduced an improved strategy to deal with a high collision rate.
Since a poor hash function e.g. which always return the location of the same bucket, can turn a HashMap into a linked list, like converting the get() method to perform in O(n) instead of O(1) and someone can take advantage of this fact, Java now internally replace linked list to a binary true once a certain threshold is breached.
This ensures performance or order O(log(n)) even in the worst case where a hash function is not distributing keys properly.
Related post:
- Difference between Hashtable and HashMap in Java
- Difference between SynchrnizedHashMap and ConcurrentHashMap in Java
- 10 examples of Hashtable in Java
- How get() method of Hashtable internally works in Java
- How to sort HashMap in Java by values
- 25 Examples of ConcurrentHashMap in Java
- How does HashMap or LinkedHashMap handle collision in Java?
- 10 ConcurrentHashMap Interview Questions with Answers
- Difference between HashMap, TreeMap, and LinkedHashMap in Java
- Java HashMap containsKey() and containsValue() Example












146 comments :
This same question was asked to me during my interview with a Investment bank for Java FIX developer position. I like follow up question though :)
Hi Sandeep,
Nice to see you here back. yes this is common core java interview question but when you ask cross question then half of developer fails. in most cases they forgot that hashmap stores both key and value in bucket.I have seen interviews where they think that only value is stored in bucket which leads to confusion when asking about duplicate hashcode.
Thanks
JAvin
Hi Dude Can we use hashMap in multithreaded scenario ? is there any issue with that ?
Good explanation. Some pictures and flowcharts will be good.
Well it is obvious that the only mandatory things to store in a dictionnary/map is the key and the value.
Without any more hypothesis, this will resort to O(n) when retriving from the key.
But O(n) is very very bad.
So you start to think at a way to have better performance. You can think about an index. You use ordered type and construct a tree.
Problem is that not all types can be ordered. The hash allow you to treat any type like an ordered one with the exception of collisions. Thus you have O(log n), but could have O(n) in worst case if all entry have the same hash.
But really I found your interview question to be confusing. I can describe what is a dictionnary, what strategy is basically used for it, but I can't say how JAVA implement it. This is a complex question that need basically that you have read the source code and that would depend of the JVM implementation you use.
And if you are really interrested for this matter you now that depending of the exact algorythm you use you have very different performance depending of your exact needs :
map with lot of entry
map with few entries.
how to optimise the partitioning what ever the hash you are given...
For hash and map keys : of course you should use only immuable key. A dictionnary/map is a nonscence if your key is mutable as it is likely that the hash change too. This is bad pratice.
I think I'm going to steal this as an interview question. Thank you for the idea :)
I took it upon myself to provide source for how to build your own (for educational purposes only) @ http://www.dzone.com/links/write_your_own_java_hashmap.html. I would expect a candidate to be able to pseudo-code something similar in an interview - or to admit they have no idea how it all actually works.
Hi Anonymous, Since HashMap is not synchronized there are issue while using it on multithreaded scenario e..g some times get() method of hashMap goes into infinite loop if rehashing and insertion occur in same time. there are other alternative available for multithreaded scenario e.g. ConcurrentHashMAp or Hashtable you can also see my article What is the difference between Synchronized Collection classes and Concurrent Collection Classes ? When to use what ?
This is really helpful.
I want to know how hashset is implemented in java. Do we need to override equals method in addition to hashcode?
Hi Pallavi,
Internally HashSet is backed by HashMap. And generally yes, in case you have custom hashCode, you may want to override equals so they are consistent with one another.
Cheers
Oleksiy
This is unrealistic, why did you focus on collisions? Java handles that problem as you pointed out, but quite frankly if you're worried about collisions maybe you should be more worried about your perception of hashing. If collisions would be the problem, then you're doing it wrong, you should not use an hashmap in the first place.
I'm sorry but discussing this sounds a bit stupid to me. If you would ask when an hashmap should be used and why, you'll be selecting better candidates.
Hi Anonymous, I appreciate your thoughts but purpose here is to check whether interviewee is familiar with some common programming concepts or not. would you like to hire a guy who is familiar with how hashmap internally works or the one who just simply used hashmap for years but never bothered to think aabout it ? on a separate note yes your question "when an hashmap should be used and why" is also a starter on this topic.
Thanks for your comment.
Put code snippets and add few points why you have used HashMap over other data structure.
Also mention some of the improvements that can be made to your HashMap code snippets. Improvement w.r.t. performance,accuracy of retrieval.
it would be nice to mention overriding equals() method?
@Ramakrishna , those are actually discussed but yes as a part of actual interview , It does make sense to ask interviewee to write equals() and hashcode() implementation for any class along with those followup.
Nice article.
Can you explain bit more about put() operation in hashmap and get() operation in hashmap. Also what happens if one thread is iterating over hashmap and other thread is put element into hashmap ? or one thread iterates over hashmap and other thread get() elements from hashmap , any code example will be good. anyway nice java hashmap interview question.
I was looking for some information on how hashmap works internally and found your site, you covered almost everything related to what is hashmap in Java, How HashMap works internally in java and more importantly how get method of hashmap works in java. kudos to you buddy. thanks a lot
Hi Anonymous 1 , put operation in hashmap is used to insert object into hashmap, put method of hashmap takes two argument one is key object and other is value object. always make sure your key object in hashmap is immutable. how get method of hashmap works is clearly explain in the article itself.
Hi,
Nice article. This was the exact sequence I was asked in an interview and I totally messed it up due to lack of knowledge about equals and hashcode methods. Hope, After reading this, I will never ever repeat the same mistake.
Hi Javin, I am working on electronic trading system which we are going to design for foreign exchange and currency trading. I have some question related to FIX Protocol and how we can use FIX Protocol for currency trading. Can you please help me. since I don't have any prior experience on writing any electronic trading system, any suggestion will be appreciated
Nice Article. I understood how the insertion & retrieval work in HashMap. However, I have a very fundamental question:
As per java,
If two objects are equal by equals() method then their hashcode must be same.
Now, what is the rule is not followed.
Lets say we have 2 objects, obj1 & obj2. Lets assume equals method returns two on these 2 objects however the hashCode returns 2 different numbers.
If we try to add these 2 objects (as key) into a hashmap, we will end up having these 2 objects(& associated values) stored in 2 different buckets. (Had the hash code returned the same numbers, the second put() method would just have updated value of the first entry). So no issue with put() method.
Now when you try to retrieve values from hashmap using those two objects, you will successfully get 2 distinct entries created above. So, what's that I am missing?
Thanks.
Hi, Is it possible to replace HashMap in Java with ConcurrentHashMap ? we have a project where hashmap has used a lot and now we want to replace that with ConcurrentHashMap.
Hi ,
Thanks for presenting this article very clearly. I have been working for more than 5 yrs in java until now but never got the proper reason behind how hashmap works.
thanks for such a information
Best
NaiveGeek
@Anonymous you can't just replace HashMap with ConcurrentHashMap because one is not synchronized at all while other provides synchronization. you probably wanted to ask replacing Hashtable with ConcurrentHashMap but even on that case you need to make sure you are not entering into race condition by using putIfAbsent() method instead of put.
I think your May 3 comment reveals that your approach is unreasonable. You say, "...I appreciate your thoughts but purpose here is to check whether interviewee is familiar with some common programming concepts or not. would you like to hire a guy who is familiar with how hashmap internally works or the one who just simply used hashmap for years but never bothered to think aabout it ?..."
Do you understand everything you've used for years? How does an internal combustion engine work? How about your microwave? How are your clothes made? You've used your body for years, so you should understand anatomy and physiology? Getting closer to programming, how is a keystroke sent to your text editor? What happens if you hit two keys simultaneously? How is the file system implemented? How does the compiler transform Java code to byte code? In Java, do you understand type erasure, generics, wildcards? By your logic, you should since you use it all the time.
Would you agree that we could find an everyday topic that you're not an expert at? If so, I think your interview should be more reasonable. Joel Spolsky is known for hiring some of the industry's truly best people; you can see how he does it here: http://www.joelonsoftware.com/articles/fog0000000073.html
@Anonymous,Thanks for your comment. I see you have a valid point but don't you agree that familiarity with common programming techniques and concept is essential especially if you are a professional programmer, A doctor definitely knows about anatomy of body , a mechanic definitely knows how internal combustion engine work. Also I have not said that don't hire a person because it just doesn't understand how hashmap works in java or what is difference between hashtable and hashmap, this question is more to see his appetite and attitude about its works and technology. Thanks for the link I been following Joel and benefited from his blog.
Awesome post. You've demonstrated your knowledge and desire to learn--you're one of the good guys, no doubt.
"... this question is more to see his appetite and attitude about its works and technology." Awesome! I agree is a fantastic thing to test an interviewee on, but I wonder if one could ask it more directly? Perhaps something like, "Can you tell me about the last time you really dug deep to understand a programming concept?" Maybe more abstractly as in "What are you passionate about?" or "What do you read?"
Thanks Anonymous for your kind comment. Yes those direct questions can be another good alternative.looking forward to see you again.
Amazing article. I wish i could have found this blog before my interview, where i was asked the very questions that you have answered. I was asked to write a HashMap implementation of my own and after reading this article it looks like i could have given a decent try.
Nice article Javin! Would be nice if you can talk more about how this discussion leads onto ConcurrentHashMap...
You have a point Gokul , ConcurrentHashMap is very popular data-structure for high frequency trading platform and it has lots of details which can be tested like Can we replace hashtable with ConcurrentHashMap, may be I will write on that sometime. Thanks for your comments.
Thanks for your comment Swapna, Sample priciple applies on hashtable as well. you may also like my article How substring method works in Java
@Viraj, @ Anonymous and @Bhaskara , Thanks for your comments guys and good to know that you like my hashmap interview experience. you may also like How Substring works in Java
This tutorial is simple and clear, very good.
May I ask a question that is about equal and hashcode?
I can't understand why the following code yield "False" ?
if( new Boolean("True") == new Boolean("True"))
System.out.println("True");
else
System.out.println("False");
I conduct 2 tests and still don't understand why the above is "False".
Boolean b1 = new Boolean("True");
Boolean b2 = new Boolean("True");
b1 and b2 is the same by the equal method
System.out.println(b1.equals(b2));
Hash code are the same
System.out.println(b1.hashCode());
System.out.println(b2.hashCode());
Thanks
because the operator "==" is used to verify the matching of objects reference, not the value. In other word you have created two distinct object using "new Boolean);" so you have different reference for two object allocated in different area of memory. I f you want compare object of same class and you want know if they have same hashcode you should use the method Equals(, it works well in this case in other case for you need to use the method compareTo() and compare().
Bye!
Hi ,
Anonymous brought up a valid point. Both equals() and hashCode() on an object should confirm the object equality. "If two objects are equal according to the equals(Object) method, then calling the hashCode method on each of the two objects must produce the same integer result." .
Hi,
Sorry but I think that asking these kind of questions in a job interview proves nothing. Today you can find anything you need on the web so there's no point in memorizing implementations of HashMap, HashTable etc.
I believe that your questions could be good if you would ask about hashing in general (two objects has the same hashcode etc).
The most important thing for a developer, TMHO, is that she could THINK, not memorize...
Kind regards
N
Isn't other collection classes which is based on hashing e.g. HashSet or LinkedHashMap also works in Same principle ? Does HashSet also use equals and hashcode to insert and retrieve objects ?
does it stores key and value object in different node in the linked list or in same node?
Hi Anonymous, keys and values of One Entry in HashMap is stored at one node and that's how after finding bucket location it finds correct object in hashmap.
Good article, but created some confusion in my mind...
If the computed hashcode is same for two objects, hashMap will override the existing value for that key.
My question is what is the scenario the value would be overriden and added to same bucket in the HashMap.
The piece of code placed here for overriding
String s1 = new String("abc");
String s2 = new String("abc");
System.out.println("s1 hashcode: "+s1.hashCode());
System.out.println("s2 hashcode: "+s2.hashCode());
Map map = new HashMap();
map.put(s1, s1);
map.put(s2, new String("cdf"));
System.out.println(map);
Hi Shivu, if key is same i.e. equals by equals method in Java than hashcode would be same and value will be replaced but if key is not same i.e. not equal but hashcode is same (Which is possible in java) than bucked location would be same and collision would happen and second object will be stored on second node of linked list structure on Map.
isn't it all other hashing related data-structure like Hashtable, HashSet, LinkedHashMap is implemented in this way ? At least implementation of put() and get() should be same with some addition specific details related to individual collection.
You are just awesome.Have no words to praise you.You have explained in such difficult thing in such a simple way.Fantastic, Great work.
Mandakini
hi,
still i have little confusion over this
can you specify an example how can two different objects has same hash code(say for two custom objects)
In fact Hashset in java is simply a delegated hashmap: here's a snippet of the source to prove the point
private transient HashMap map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// similar methods that delegate follow
Thanks for such nice article. Will be expecting such articles in future also.
@MJB, Indeed HashSet uses HashMap for hashing support and thank for putting the code snippet it makes the point much clearer.
@Mandakini Mishra , Thanks for your kind words, glad to hear you like this Java hashmap question answer article.
This is a great article, but if i have one complaint, it seems to be written poorly in terms of english (almost as thought a translator was used). i am finding it hard to understand some of the answers because of this.
I have one comment regarding your explanation: key.equals() is used also when you use put() method, because if hashcode() of an existing key is the same with the one which you want to insert, yes, the new key will be the next one in the bucket, ONLY IF THE KEY IS UNIQUE. So in order to do that, it is used also method key.equals(), to prevent duplicates. (You said that we are talking about equal() method only when we are retriving data from HashMap)
Regards
@Anonymous, your observation is correct key.equals() is used on both put() and get() method call if object already exits in bucked location on hashmap and that's why tuples contains both key and value in each node. thanks for pointing it and making it more clear.
Hi,
Overriding equals and hashcode we can make the object as key in hashmap.While putting the the reference to the object as Key in hashmap or creating the object and setting it in put method , what difference does it make in retreiving the object?
@Tofeeq thanks for your comment. Glad to hear that you like interview question on java hashmap.
Thanks Javin, great post again.
This is true that Hashmap are common questions someone can get in interview from a Java & Java EE perspective. I interview new members myself at my current company (CGI Inc.) and the typical questions that I ask, in a Java EE context are:
- What are best & known risks when using Hashmap data structure?
- What JDK Map data structure is more suitable to handle concurrent read & write operations in a Java EE environment?
The answer for the first one is all about adding proper synchronization when Hashmap is used in a concurrent Thread access scenario e.g. same Hashmap instance shared across multiple Threads.
Primary known risks are Hashmap internal index corruption and infinite looping, which can bring your JVM to its knees.
The answer about the second one is to use the ConcurrentHashMap, introduced in JDK 1.5, which provides Thread safe operations but no blocking get() operation; which is key for proper performance. This is the typical data structure used these days in modern Java EE container implementations.
If your readers are interested, I have a case study of a recent Hashmap infinite looping problem, actual Weblogic 11g defect (non Thread safe Hashmap)!
Thanks again for all that good work.
P-H
I am new to Java World! So I have this problem stated as under.....
I have sortedHashMap and hashMap2
Now i have to get hashMap3 based on sortedHashMap sorted order.
Secondly; I have also to limit hashMap3 as of first sorted 100 values.....rest map I dont need.
Please suggest me coding example or junk of code.
Thanks!
I was always curious on How HashMap stores object in Java or How HashMap is implemented in Java. I know about bucket and collision but What I missed was Map.Entry which is used to store both key and value object. HashMap stores Entry object which contains both key and value which then used in case of collision when more than one object is stored inside bucket to find out correct mapping. Correct me if this is not how hashmap stores objects in Java.
Isn't it Hashtable also works in similar way. Please let us know How Hashtable works in Java. I know about HashMap but now I am keen to know How Hashtable works internally.
Hi Javin,
Nice artcile..nicely explained..it wud have been great it u cud explain the rehashing of Hashmap and the concurrent thread access in Hashmap.
Excellent article....
But I would correct on one point.
>What will happen if two different HashMap key objects have same hashcode?
>They will be stored in same bucket but no next node of linked list. And keys equals () method will be used to identify correct key value pair in HashMap.
The next node of the linked list will point to the next object in the same bucket.
I liked a post a lot .
I am undertaking interviews and i know that these questions are really difficult to ans , inspite of working on hash map , we generally forget these details .
Thanks
Thanks a lot. Pretty clear :) :)
Thanks for the post.Its really useful.
1)Can you be more clear on using the final immutable objects as keys?
2) what are the advantages of having final immutable objects as keys?
3)Does they have any performance impact while getting the hashcode or while performing the equals method?
I feel Collision should actually happen to improve the performance.Only then there will be a performance gain while searching for an object.If 1000 objects have 1000 different hashcodes, we will end up with 1000 hash buckets and each containing only one element.In that case, there wont be any use of hashmap and it's same as Arraylist.
4)So, How do we make sure that multiple objects have the same hash code?
5) Hash map should have unique keys right.So if we try to insert an object with the key that was already present in the HashMap, why does it not throw any exception.Instead it will replace that value object in the HashMap.Is there any reason for this?
6) Why did they implement this key value pair? I mean Why cant it be just the value object thereby making the HashMap calculating the hascode of value and use the same while retrieving?If we dont want a key value pair and just want to improve search performance, then is it not this key value pair adding overhead to performance? If I want the same fucntionality as hashmap but dont need the key value pair, which collection do you suggest?
Sorry for more questions on this.. I just thought to be very much clear on this HashMap concept.
Please let me know if am not clear.
Nice explanation of internal logic of HashMap. But I think this focuses on pre Java 5.
It uses HashMap.Entry for storing key-value not linked list. Very nice and clever use of Entry object.
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
Excellent article and explanation. Got all the questions cleared. Thanks
Can you please explain "if race condition happens then you will end up with an infinite loop" bit more.
Thank you for nice article
good writeup,, useful
thanks-BIGB
Awesome work, u have covered almost everything in hashmaps -one of the most difficult part in collection to understand. Keep up the good work!! I wish if you could include some examples in coding, that would make an interviewee like me more confident to express it in front of interviewer.
is there any change in HashMap in Java 5 and Java 6, which affects internal working of HashMap in Java or HashMap in Java 5 is exactly same in HashMap in Java 6 or JDK 4 ?
please explain "if race condition happens then you will end up with an infinite loop" bit more.
it is better if you provide simple example!:)
One more question on Java HashMap:
Question: why hashmap keys needs to be immutable ?
Answer : HashMap keys needs to be immutable so that no one can modify key once created leaving its hashCode unchanged which is used to put and get object from HashMap. If HashMap key is not immutable than key can return hashCode 100 while putting object and after some modification hashCode changes to 102, means you can not get object back from HashMap.That's why hashmap keys needs to be immutable in Java
Diff between HashMap & Hashtable interms of algo for the key index will be
HashMap
Index = hashcode & (bucketsize) // bitwise
Hashtable
Index = (hashcode & 0x7FFFFFFF) % bucketsize // MOD op e.g 100(hashcode) % 10 (bucket size) = 0
Index = 0
Hi Javin,
Your readers may be interested in a recent post on HashMap vs. ConcurrentHashMap from my Blog.
Article was created following a recent production problem from one of my client Java EE environment. It compliments well your great post.
A sample Java program is also provided on how to replicate this infinite loop condition for get() and put() operations.
Enjoy.
Regards,
P-H
Good one. But I have a question. How does an entry with null key is handled in Hashmap? I mean, one can't calculate hashcode on null so how could an entry with null key get a bucket?
Suppose it is placed at 0 th bucket, but then if 0 th bucket has multiple entries in the linked list (the entries whose keys got hashcode 0 when calculated.) Then how is it resolved, as we can't even call equals method on null!
I case of hashCode collision, equals method is applied in same bucket with existing elements, if equals method return true, new value is applied on the old key value combination, if equals return false new entry is made with new key value in same bucket.
--Sanjeev
http://all-technicals.blogspot.in
do you see any problem with resizing of HashMap in Java
I do not understand how the race condition will occur can you elaborate?
I really like all your posts, very informative!
I did not understand how race condition will cause infinite loop in hashmap resizing...could you please explain?
We create two diff hashmap.
while inseting records is there any chances of having same hashcode.
Hi I am being a big fan of you now. Just a little bit of problem.
If storing hashmap in java can be explained in more detail. if some diagrams can be included.
@Anonymous, Thanks. I would definitely try to include a diagram to explain internal working of HashMap in more details.
Hi
You say that put() method does not use equals() method on key objects, is that right?
See below example:
HashMap hm = new HashMap();
hm.put("a", "A");
hm.put("a", "NOT A");
In this example how does HashMap only returns "Not A" value.
Thanks,
@Anonymous, This is how I see,
1) When you first put "a" as key and "A" as value, HashMap calls "a".hashCode(), which returns a bucket location inside HashMap. if there is no object there than Java will store an entry object which contains both key and value there. If there is collision than, a linked list will be created and an entry corresponding to "a" and "A" will be stored there.
2. Now when you again insert same key, same bucket location will be found, and Java will search for an entry, whose value matches with "A". If found then it would be replaced.
But, YES, Java HashMap uses equals method of key to find correct entry.
Here is the code from java.util.HashMap which clarifies the doubt
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
I am currently in an entry-level Java class and we were asked to implement a Map interface using an ArrayList of LinkedLists without any prior experience with this topic. This article has been beyond helpful. Thank you, thank you, thank you!
Just to add here are few more interview question asked on java
How does load factor and. Initial capacity affect performance of hashmap
Why hashmap always use capacity as power of two?
@ketaki_w,
Hashmap allows only one entry with null key. It maintains a separate bucket for null key. When we try to insert any data, put method checks if the key is null. If the key is null, it will insert the entry into the separate bucket maintained for null key. Else, continues with normal logic. Below is the code snippet from the Hashmap source code.
public V put(K key, V value) {
if (key == null) {
return putForNullKey(value);
}
... //Non-null key data insertion logic here.
...
}
/**
* Offloaded version of put for null keys
*/
private V putForNullKey(V value) {
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
as per ur explanation of load factor , loadfactor is sumthing by which the collection is scaled up.
@Anonymous
HashMap always uses a power of two for its length to be able to calculate the index really fast (much faster than mod operation), doing a bitwise AND operation between the hashcode and length-1, which just returns the lesser bits. But for this, length has to be a power of 2.
Regarding this statement:
important point to mention is that HashMap in Java stores both key and value object as Map.Entry in bucket which is essential to understand the retrieving logic
Actually, each Map.Entry contains 4 items:
- key
- value
- hashcode
- next pointer to next Map.Entry in bucket list
As the linked list of Map.Entry items in the "bucket slot" is traversed, the hashcode must match and either the address of the key or its hashcode must match:
// e is the pointer to a Map.Entry
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
// found it
return e.value
So if two different keys happen to have the same hashcode, then the 2nd test (for key being at same (==) memory location or being equals()) will correctly find the correct key in the linked list.
Finally, since the equals() test might take some finite computational time, the code in get() method is optimized to avoid calling equals() unless absolutely necessary. If the e.hash is wrong, there is no need to test for equality. But if the e.hash is correct, and if the address of the search object is the same as the address of the stored object in the Map.Entry, then the call to equals() also is avoided.
The only time the equals() method would be called is if your key inserted with put() is different memory address from the key being looked up:
// HashMap
Key key = new Integer(1);
map.put (key, "one");
String value = get (new Integer(1) ); // differet address
-dbednar
Maybe another good interview question MIGHT BE as follows:
What problems could arise with HashMap if the key were mutable?
Answer: If the key is immutable, then no problems will arise (since the hashcode cannot change). However, if the key is mutable, and is able to change the key in such a manner as to change the hashcode, then you might insert the key, but be unable to retrieve it later.
The reason this can happen is that since the hashcode changed, the index into the bucket array used for the insertion (put(K,V)) might be different than the index for the lookup (get(K)). Since different linked lists are used, and the lookup will search the wrong linked list, and so will return null to mean not found (or null if null value is permitted).
-dbednar
Anonomous asked:
> Hi Dude Can we use hashMap in multithreaded scenario ? is there any issue with that ?
Yes, big problems. For thread-safety, its best to use ConcurrentHashMap, introduced in JDK 1.5.
-dbednar
Hi Volodymyr, You have raised a good point, HashMap implementation has some issue with String keys, because of it's hashCode implementation. Since HashMap uses linked list in case of collision, this can result in performance of O(n) instead of O(1). A Crafted set of String keys can be used in Denial of Service (DOS) attack, where an application server like Tomcat or JBOSS build Hashtable or HashMap with untrusted input retrieved from HTTP request parameter. Thankfully, Java 8 is fixing this HashMap bug, by replacing linked list with balanced tree, once number of element in linked list crossed a threshold. This fix can improve performance from O(n) to O(logN) in case of such collisions. This can also reduce such denial of service attack, which can hamper your server badly.
Hi,
This is Wonderful blog...,i am addicted to it.
Thanks
Hey Javin,
After reading this article for several times, I have a question. In case of conflicts i.e when two hashcodes are equal, key's equal method is used in the bucket to identify the exact key/value pair. However, doesn't key.equal again use the hashcode() method to compare, which would result in same hashcode() again?
Hi,Javin,
I am confused by this paragraph
"What will happen if two different HashMap key objects have same hashcode?
They will be stored in same bucket but no next node of linked list. And keys equals () method will be used to identify correct key value pair in HashMap ."
From above, I conclude if two keys have same hashcode, they would be put in same bucket and chained in a linked list. And even two different keys have different hashcode, they still might be put in same bucket and chained in a linked list.
Is there something wrong in my understanding?
HI http://java67.blogspot.sg/2013/06/how-get-method-of-hashmap-or-hashtable-works-internally.html,
I am adding some few question on Hashmap asked by interviewer. Please post these ans in your blog it will be helpful to others.
1. Can hashMap store 2 Diff value with same key?
2. Hashcode and Equals method overriding is compulsory for HasMap and why?
3. What is importance for overriding hascode and equals method, Key or value or both and how?
Hi All,
I have one small doubt, In case of collision while storing data in to the memory. Is one bucket location contains multiply Entry Object for same bucket location. I am really not able to visualize this.
This is really good. I am preparing for an investment bank. Hope they ask me and I ll burst it out! :D
On February 7, 2011 at 3:42 AM , Anonymous asked
Can we use hashMap in multithreaded scenario ? is there any issue with that ?
I have explained the same using a practical example on my blog.
Please check this blog for a demo of what I have mentioned above. Please correct me if my understanding is wrong somewhere.
http://ganeshrashinker.blogspot.in/
hi,
from this articale i understood that hashmap allow null value,so when i store a value which has null as
key then how hashing will takes place and what hashcode generated for null values.
2.can any one please explain in which case that hashing of two key generate the same hashcode?
3.does it appropriate hashmapobj.get(null) when i store a value that associate null as key?
Hi,
As per the article "HashMap doesn't append the new element at tail instead it append new element at head to avoid tail traversing" . But anyway it get traversed to check same key , so what do you mean by tail traversing here?
Hi
How can you create own hash map with out using java api
Does hashmap always uses LinkedList for storing??
Why to use HashMap?
HashMap in java 1.7 does not handle Collisions. It u try to add a duplicate key, it will get replaced by the new key. Can somebody confirm ?
Thanks for explaining in simple language..
My question is regarding size of HashMap.
1.When will rehashing be done?.
suppose 16 is the initial size and i have added 12 ie. 16*0.75 element into hashmap. is it irrespective of element being added to same or different bucket?
2. cane we set default size? if yes than how?.
While rehashing, if two thread at the same time found that now HashMap needs resizing and they both try to resizing. on the process of resizing of HashMap, the element in bucket which is stored in linked list get reversed in order during there migration to new bucket because HashMap doesn't append the new element at tail instead it append new element at head to avoid tail traversing. If race condition happens then you will end up with an infinite loop.
Please explain above paragraph. I failed to understand below points -
1. Why list is getting reversed while rehashing. I mean what advantage we got ?
2. Why elements are getting added at front end of list ? Why not tail end ?
do you know whether HashMap is safe from DOS attack or not? What happen if hash function return same value for multiple keys? If yes, how do you fix that, how do you make sure that it doesn't perform on O(n) level?
Just to add my 2 cents,
HashMap now(i.e. JDK-8) uses balanced tree during collision. http://openjdk.java.net/jeps/180
What a brilliant collection...
Well i dont know if people will really have patience to come down here and read this comment, and i also dont know if this question has already been covered, here's what was asked from me:
When you create a hashmap object using Hasmap h = new hashmap(), the constructor here can accept arguments.These can be upto 2. what are these arguments meant for?
I pretty much didnt know the answer then. The answer is:
HashMap()
Constructs an empty HashMap with the default initial capacity (16) and the default load factor (0.75).
HashMap(int initialCapacity)
Constructs an empty HashMap with the specified initial capacity and the default load factor (0.75).
HashMap(int initialCapacity, float loadFactor)
Constructs an empty HashMap with the specified initial capacity and load factor.
Sometimes interviews do make you explore.. Thanks to the interviewer!!! :)
@Solutions,
while calling get()method
1) hashCode of key object is used to find bucket location in HashMap.
2) if in bucked location only one object is there than its value object. else if bucket location contains LinkedList than traverse through each node and compare key object stored as tuple along-with value object to key object passed to get() method by using equals() method. if matches than return the value object. point to note was that instead of just storing value object, LinkedList node on HashMap also stores Key object.
@Sriram,
HashMap key object must be immutable in order to be used as key because hashCode of key is used to find the bucket location inside HashMap and retrieve object. if Key object is mutable than any one can change its value after putting object in HashMap and than calling hashCode() on modified key object would have produce different hashcode and consequently different bucket location and you will never be able to retrieve object from HashMap. hope this would be clear
Hello!
I also wanted to point out of Integer as a key.Integer's hashCode is value you provide instantiating Integer. Therefore If you try to put two mappings with keys as Integers and those Integers hold the same value the second mapping will replace the first one because keys will be considered equal with identical hashCode
String is not considered good key for HashMap. Because of weak hash-code calculation of String !!!
If you want to know more about internal HashMap read my tutorial Internal life of HashMap in Java.
When I put null into map as map.put(null,"demo") and later do operation for getting value "demo" by passing null as key, How does it work? Since on hashmap firstly key of hashcode is used to find bucket and later equals() is used to find the value but what in case of null? how equals and hashcode methode work in this case ?
Hello Anonymous, I have added another section to explain how null key is stored and retrieved in HashMap. When you call map.put(null, "demo") then corresponding entry is stored in first location in bucket array i.e. index 0. when you call get(null) value is retrieved from that location. Two special method putForNullKey() and getForNullKey() are used to put and get null key from HashMap.
Do you know Why HashMap stores both keys and values in Entry? Why not just store values only?
There are multiple ways to resolve collision in hash table. HahsMap in Java i.e.java.util.HashMap uses chaining to resolve collision. Another way to resolve hash collision is by using "Open addressing". If you are going for Java interview, you better know both of them
@Anonymous, HahsMap stores both key and value inside Entry object because it's possible to store more than one value in one bucket location, in that case in order to find the correct value corresponding to key, you also need the key object there. this is exactly where equals() method comes into play.
Please explain how remove(key) method internally works on HashMap??
This was one of my interview questions.
Can you write a similar article on "How treemap works using Red Black ago"?
Hi Javin,
This is a nice article. But I have one question here
Why there is only one null key allowed in Hashmap.Why can't we insert many
@Anonymous, null handling is very special, I would suggest to check the section about how HashMap handles null keys. To give you answer, multiple null is not an option because HashMap doesn't allow duplicate keys.
Hi Javin,
Could you please explain how hava 8 uses balanced tree to solve the collision issue.
How they will create the balanced tree, as keys has same hash code
race condition in hashmap with picture
http://mailinator.blogspot.in/2009/06/beautiful-race-condition.html
Hi,
As per HashMap implementation, HashMap resizes its internal table size when number of elements are >= Load factor * Initial Capacity i.e, 12
To test this I debugged below code:
public class HashMapTest {
public static void main(final String[] args) {
Map test = new HashMap();
System.out.println("Initial Default HashMap size : -" + test.size());
for (int i = 0; i < 16; i++) {
test.put(i + "", i + "");
}
System.out.println("HashMap size After adding 11 Elements: -" + test.size());
test.put("11", "11");
System.out.println("HashMap size After adding 11 Elements: -" + test.size());
test.put("12", "12"); //13th Element
System.out.println("HashMap size After adding 11 Elements: -" + test.size());
}
}
In above code it should resized the Table size while adding 13th element but I found table size to be 16 instead of 32.
Can anyone explain me please ?? Thanx
@Anonymous -
test.size() always returns the actual count of keys held by the HashMap, no matter what is size of the internal table. Size of internal table is always higher than number of entries in the HashMap, and is expanded once number of entries reach certain threshold, which is determined by the load factor. Higher size of internal table provides capacity to accommodate addition of newer entries without having to rehash the entire table. Without any additional capacity in the table, hash-values of each entry has to be recalculated every time a new entry is added.
I like your post. You explained it very well.
For those who are not clear on race condition which may cause infinite loop in Hashmap: http://javabypatel.blogspot.in/2016/01/infinite-loop-in-hashmap.html
This explanation helps me a lot for interview....
what is the time complexity of insert, delete and update in hashmap in Java?
Hi Paul, superb post..especially that diagram.
1) next variable in Entry object needs more highlight
2) If we are putting multiple entries with same keys. Result of get is entry of latest key. But how it work internally.
As while putting only hashCode of key is calculated.
Why does one should use null as a key in HashMap?
@Tappan Patnaik For representing default case.
"Java now internally replaces linked list with a binary tree once certain threshold is reached."
You have so many grammatical mistakes that it's hard to read ...
Still a great article, thanks a lot
This article is AMAZING!!! Explained everything so clearly! Nice work!
Hashmap allows only one null key.But what is the use of null key in Hashmap?
@Unknown, good question, but I have never come across any good reason with the use of null keys, only practical benefit I see is that it doesn't throw NullPointerExcepiton by calling equals() and hashcode() on null keys.
It is a great article, It really helped me. I have faced one more question in an interview and would like to share with you all.
What Hashcode actually represents ? Does it represent memory location of an object or it is just an identifier or its a combination of both the options mentioned ?
Hello @Anonymous, if you read the Javadoc of hashCode method you will get your answer. Hashcode is an integer value which is generated by converting internal memory address of object to an integer.
Hi,HashMap is important topic in java, to learn in depth about How HashMap works in Java http://beyondcorner.com/hashmap-works-internally/
Java now internally replace linked list to a binary true once certain threshold is breached.
Kindly correct the spelling mistake . your blog is really good . I have been reading it for many years .
how to generate the hashcode of the object for example Employee e1=new Employee(). and this is put in map, suppose map.put(e1,"shubhangi"); please tell me how to generate the e1 of hashcode
thanks for this helpful guide
Hi,
Can anyone tell me if 0 index in hash table is reserved for null key, then what will happen if hash key w.r.t a key in the HashMap is 0. In which index of hash table it will be saved.
Hello @Unknown, the bucket location ( index in array) is returned by a hash function, which only return 0 if key is null for other keys it return non-zero index. Also, in worst case, if a collision happens then chaining is used, I mean a linked list is used to store both keys into same location.
Thank you Javin, your new diagrams are really nice,
My question is, when the Valhalla project makes the "type generic" with specialization, will it be possible to test whether the value has the type specified in the Hashmap and return an error at compile time?
Hello LucianoViana, Yes, with Valhalla project's "type generics" with specialization, it will be possible to test whether the value has the type specified in the HashMap and return an error at compile time.
This is going to be one of the game changing feature as this feature would not only allow for compile-time type checking in HashMaps, ensuring that values added to the map adhere to the specified type but also enhance type safety, improve error messages, and potentially lead to performance gains.
While the Valhalla project is still in development, the future of Java generics looks promising with the potential for more robust and efficient code.
Great explanation of how HashMap works in Java! The breakdown of hashing, buckets, and handling collisions really helps clarify what’s happening under the hood. It’s especially useful for developers preparing for interviews or improving their Java performance tuning skills.
I recently came across some similar learning material https://brollyacademy.com/ — they have detailed training programs that complement these Java concepts quite well. Thanks for sharing such a valuable post!
Post a Comment