Hello, guys if you are preparing for the Java Developer or Apache Kafka interview and looking
for frequently asked Apache Kafka interview questions and answers then you have come
to the right place. Earlier, I have shared the best Kafka courses and popular interview questions on Java, JMS, Spring Boot, and Hibernate and in this article, I Am going to share 20 frequently asked Apache
Kafka interview questions with answers. Over the years, Kafka which is
developed by Apache Software Foundation has gained popularity because of its immense capability of data processing and become a standard tool for high-speed and reliable messaging.
Apache Kafka provides a unified, high-throughput,
low-latency platform for handling real-time data feeds and because of that it has become a go to choice for high-speed message for many fortune 500 companies.
The success of Apache Kafka can be attributed to its distinct characteristics,
which make it a highly appealing solution for data integration. Scalability,
data splitting, low latency, and the capacity to accommodate a large number
of different consumers make it an excellent choice for data integration use
cases.
A slid knowledge of Apache Kafka will not only add an additional qualification to your resume but also makes you eligible for many jobs at top companies like LinkedIn, Goldman Sachs, Citi and many other companies which uses Apache Kafka in production.
A slid knowledge of Apache Kafka will not only add an additional qualification to your resume but also makes you eligible for many jobs at top companies like LinkedIn, Goldman Sachs, Citi and many other companies which uses Apache Kafka in production.
If you're planning on attending a Java Developer interview where Apache Kafka skills are needed or you are going for an Apache
Kafka interview soon, take a look at the Apache Kafka interview questions
and answers below, which have been carefully curated to help you ace your
interview. So let's have a look into this.
20+ Apache Kafka Interview Questions with Answers for Java Programmers
Here is a list of frequently asked Apache Kafka interview questions for
Java programmers and software developers who are preparing for the Apache
Kafka interviews or Java Developer interviews where Apache Kafka skills are needed.
These questions cover most essential Kafka concepts like
topics, replication, partitions, etc and you can use them to quickly
revise essential Apache Kafka concepts before interviews.
1. What is Apache Kafka?
Apache Kafka is a stream-processing framework that implements a software bus. It is a Scala and Java-based open-source development platform developed by the Apache Software Foundation. The goal of the project is to provide a single, high-throughput, low-latency platform for real-time data flows.
1. What is Apache Kafka?
Apache Kafka is a stream-processing framework that implements a software bus. It is a Scala and Java-based open-source development platform developed by the Apache Software Foundation. The goal of the project is to provide a single, high-throughput, low-latency platform for real-time data flows.
Kafka Connect allows
users to connect to external systems (for data import/export) and
includes Kafka Streams, a Java stream processing framework.
Some key features of Apache Kafka are given below,
1. High Throughput - Supports millions of messages
2. Scalability - Highly scalable distributed systems with no downtime.
3. Replication - Messages are duplicated across the cluster to enable numerous subscribers.
4. Durability - Support for persistence of messages to disk.
5. Stream processing - Used in real-time streaming applications.
2. What are the various components that you can see in Apache Kafka?

3. What is a consumer group?
Consumer Groups are a feature unique to Apache Kafka. In essence, each Kafka consumer group is made up of one or more people who consume a collection of related topics at the same time.
4. What is the ZooKeeper's function in Kafka?
Kafka uses ZooKeeper to manage the cluster. ZooKeeper is used to coordinate the brokers/cluster topology. ZooKeeper is a consistent file system for configuration information. ZooKeeper gets used for leadership election for Broker Topic Partition Leaders.
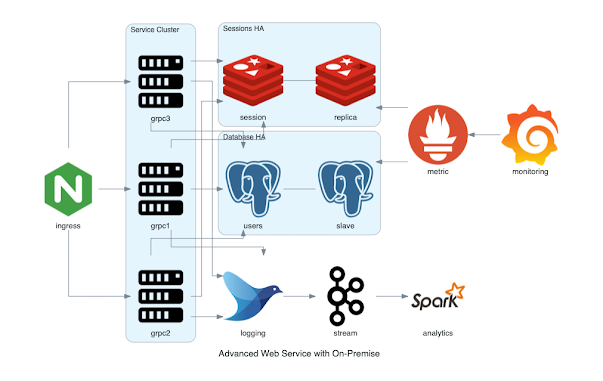
5. What is the meaning of Partition in Kafka?
Kafka topics are divided into partitions, with each partition containing records in a predetermined order. Each record in a partition is assigned and attributed a unique offset. A single topic can contain many partition logs.
9. How to expand a cluster in Kafka?
A server just has to be given a unique broker id and Kafka must be started on that server to be added to a Kafka cluster. A new server will not be provided to any of the data divisions until a new topic is formed.
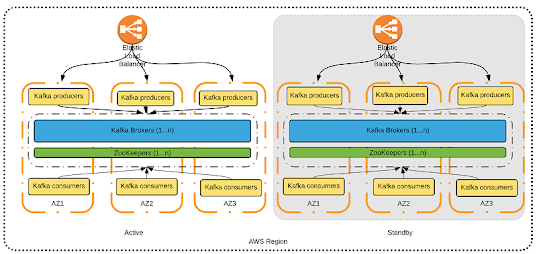
10. How does Kafka define the terms "leader" and "follower"?
Each partition in Kafka contains a single server acting as the Leader and 0 or more servers acting as Followers. The Leader is responsible for all read and writes operations to the partition, while the Followers are responsible for passively replicating the leader.
11. In a Kafka cluster, what is the difference between a partition and a replica of a topic?
Partitions are a single Kafka theme fragment. It's possible to change the number of partitions per subject. More divisions allow for more parallelism while reading from the subjects. The number of divisions in a consumer group has an impact on the consumer group.
Replicas are identical copies of the partitions. They are never spoken to or read aloud to. Their main purpose is to provide data redundancy. When there are n copies of a subject, n-1 brokers can fail without incurring data loss.
16. What are the main API'of Apache Kafka?
Apache Kafka has 4 main APIs:
1. Producer API
2. Consumer API
3. Streams API
4. Connector API
17. What is the traditional method of message transfer?
Two techniques of message transmission are used in the traditional method:
1. Queuing:
2. Publish-Subscribe:
.jpg)
18. What is the purpose of the Streams API?
The Streams API lets an application act as a stream processor, consuming input streams from one or more topics and supplying output streams to one or more output topics, as well as effectively transforming input streams to output streams.
19. Explain Kafka's concept of leader and follower?
Some key features of Apache Kafka are given below,
1. High Throughput - Supports millions of messages
2. Scalability - Highly scalable distributed systems with no downtime.
3. Replication - Messages are duplicated across the cluster to enable numerous subscribers.
4. Durability - Support for persistence of messages to disk.
5. Stream processing - Used in real-time streaming applications.
2. What are the various components that you can see in Apache Kafka?
Here are key components of any Apache Kafka cluster:
- Topic - a stream of messages belonging to the same type
- Producer - this is the one who can publish messages on a topic.
- Brokers - Servers which is used to store the publisher's messages.
- Consumer - subscribes to various topics and pulls data from the brokers.
3. What is a consumer group?
Consumer Groups are a feature unique to Apache Kafka. In essence, each Kafka consumer group is made up of one or more people who consume a collection of related topics at the same time.
4. What is the ZooKeeper's function in Kafka?
Kafka uses ZooKeeper to manage the cluster. ZooKeeper is used to coordinate the brokers/cluster topology. ZooKeeper is a consistent file system for configuration information. ZooKeeper gets used for leadership election for Broker Topic Partition Leaders.
5. What is the meaning of Partition in Kafka?
Kafka topics are divided into partitions, with each partition containing records in a predetermined order. Each record in a partition is assigned and attributed a unique offset. A single topic can contain many partition logs.
This permits several people to read at the same
time from the same topic. Partitions, which divide data into a single
topic and distribute it among multiple brokers, can be used to
parallelize topics.
6. What is the maximum size of a message that Kafka can receive?
By default, the maximum size of a Kafka message is 1MB (megabyte). The broker settings allow you to modify the size. Kafka, on the other hand, is designed to handle 1KB messages as well.
7. Name some disadvantages of Kafka?
There are many advantages and also disadvantages to using Apache Kafka. Some of the disadvantages are given below.
1. Certain message types like point-to-point queues and request/reply are not supported by Kafka.
2. There are no complete monitoring tools in Apache Kafka.
3. When messages are tweaked, Kafka's performance suffers. Kafka works well when the message does not need to be updated.
4. Kafka does not support wildcard topic selection. It's crucial to use the appropriate issue name.
8. What are the benefits of using clusters in Kafka?
A Kafka cluster is essentially a collection of brokers. They're utilized to keep things balanced. Because Kafka brokers are stateless,
6. What is the maximum size of a message that Kafka can receive?
By default, the maximum size of a Kafka message is 1MB (megabyte). The broker settings allow you to modify the size. Kafka, on the other hand, is designed to handle 1KB messages as well.
7. Name some disadvantages of Kafka?
There are many advantages and also disadvantages to using Apache Kafka. Some of the disadvantages are given below.
1. Certain message types like point-to-point queues and request/reply are not supported by Kafka.
2. There are no complete monitoring tools in Apache Kafka.
3. When messages are tweaked, Kafka's performance suffers. Kafka works well when the message does not need to be updated.
4. Kafka does not support wildcard topic selection. It's crucial to use the appropriate issue name.
8. What are the benefits of using clusters in Kafka?
A Kafka cluster is essentially a collection of brokers. They're utilized to keep things balanced. Because Kafka brokers are stateless,
Zookeeper is used to maintain track of the state of their cluster.
Hundreds of thousands of reads and writes per second can be handled by a
single Kafka broker instance, and each broker may handle TBs of messages
without sacrificing speed.
The Kafka broker leader can be chosen using
Zookeeper. As a result, having a cluster of Kafka brokers greatly
improves performance.
9. How to expand a cluster in Kafka?
A server just has to be given a unique broker id and Kafka must be started on that server to be added to a Kafka cluster. A new server will not be provided to any of the data divisions until a new topic is formed.
As a result, whenever a new machine is added to the cluster,
some old data must be transferred to the new machines. The partition
reassignment tool is used to move some partitions to the new broker.
10. How does Kafka define the terms "leader" and "follower"?
Each partition in Kafka contains a single server acting as the Leader and 0 or more servers acting as Followers. The Leader is responsible for all read and writes operations to the partition, while the Followers are responsible for passively replicating the leader.
11. In a Kafka cluster, what is the difference between a partition and a replica of a topic?
Partitions are a single Kafka theme fragment. It's possible to change the number of partitions per subject. More divisions allow for more parallelism while reading from the subjects. The number of divisions in a consumer group has an impact on the consumer group.
Replicas are identical copies of the partitions. They are never spoken to or read aloud to. Their main purpose is to provide data redundancy. When there are n copies of a subject, n-1 brokers can fail without incurring data loss.
Furthermore, no subject's replication factor can be greater than
the number of brokers.
12. Is it possible to get the message offset after producing?
You can't do that from a class that acts like a producer, which is what most queue systems do; its job is to fire and forget messages. The rest of the work, such as suitable metadata processing with ids, offsets, and so on, will be handled by the broker.
You can acquire the offset from a Kafka broker as a message consumer. If you look at the SimpleConsumer class, you'll note that it gets MultiFetchResponse objects with offsets stored in a list. Furthermore, when you iterate the Kafka Message, you'll get MessageAndOffset objects, which contain both the offset and the message transmitted.
13. What is Geo-Replication in Kafka?
Kafka Geo-replication is supported by MirrorMaker for your clusters. Messages are duplicated across various datacenters or cloud regions using MirrorMaker. This can be used in active/passive scenarios for backup and recovery, as well as in inactive/active scenarios to move data closer to your users or meet data locality needs.
14. Why replication is required in Kafka?
Message replication in Kafka ensures that any published message is not lost and may be consumed in the event of a machine failure, a program failure, or more common software upgrades.
15. What are consumers in Kafka?
Kafka offers a single consumer abstraction that may be used to discover both queuing and publish-subscribe Consumer Groups. They assign themselves to a user group, and each message on a given topic is sent to one use case within each promising user group.
12. Is it possible to get the message offset after producing?
You can't do that from a class that acts like a producer, which is what most queue systems do; its job is to fire and forget messages. The rest of the work, such as suitable metadata processing with ids, offsets, and so on, will be handled by the broker.
You can acquire the offset from a Kafka broker as a message consumer. If you look at the SimpleConsumer class, you'll note that it gets MultiFetchResponse objects with offsets stored in a list. Furthermore, when you iterate the Kafka Message, you'll get MessageAndOffset objects, which contain both the offset and the message transmitted.
13. What is Geo-Replication in Kafka?
Kafka Geo-replication is supported by MirrorMaker for your clusters. Messages are duplicated across various datacenters or cloud regions using MirrorMaker. This can be used in active/passive scenarios for backup and recovery, as well as in inactive/active scenarios to move data closer to your users or meet data locality needs.
14. Why replication is required in Kafka?
Message replication in Kafka ensures that any published message is not lost and may be consumed in the event of a machine failure, a program failure, or more common software upgrades.
15. What are consumers in Kafka?
Kafka offers a single consumer abstraction that may be used to discover both queuing and publish-subscribe Consumer Groups. They assign themselves to a user group, and each message on a given topic is sent to one use case within each promising user group.
The user instances are
now disconnected. Based on the customer groupings, we can determine the
consumer's messaging model.
If all consumer instances have the same consumer set, this behaves similarly to a traditional queue that distributes the load across consumers.
If all consumer instances have the same consumer set, this behaves similarly to a traditional queue that distributes the load across consumers.
When all customer instances
have different consumer groups, the system behaves as a
publish-subscribe, and all messages are sent to all customers. If you need example, you can see this Java + Spring + Apache Kafka Producer Consumer Example.
16. What are the main API'of Apache Kafka?
Apache Kafka has 4 main APIs:
1. Producer API
2. Consumer API
3. Streams API
4. Connector API
17. What is the traditional method of message transfer?
Two techniques of message transmission are used in the traditional method:
1. Queuing:
Queuing allows a group of consumers
to read a message from the server, and each message is delivered to one
of them.
2. Publish-Subscribe:
Messages are broadcast to all
consumers under this model. Kafka caters to a single consumer
abstraction that encompasses both of the aforementioned- the consumer
group.
18. What is the purpose of the Streams API?
The Streams API lets an application act as a stream processor, consuming input streams from one or more topics and supplying output streams to one or more output topics, as well as effectively transforming input streams to output streams.
19. Explain Kafka's concept of leader and follower?
In Kafka, each partition has one server that acts as the Leader and one
or more servers that operate as Followers. The Leader manages the read
and writes requests for the partition, while the Followers are in charge
of passively replicating the leader.
One of the Followers will take over
if the Leader is unable to lead. As a result, the server's burden is
distributed evenly.
20. Can Kafka be used without a ZooKeeper?
It is not feasible to connect directly to the Apache Server without going through the ZooKeeper in Kafka. As a result, the answer is no. If the ZooKeeper is unavailable for any reason, no client requests will be fulfilled.
20. Can Kafka be used without a ZooKeeper?
It is not feasible to connect directly to the Apache Server without going through the ZooKeeper in Kafka. As a result, the answer is no. If the ZooKeeper is unavailable for any reason, no client requests will be fulfilled.
21. What is difference between Apache Kafka, RabbitMQ, and ActiveMQ? (Answer)
22. Why Kafka is so fast compared to other messaging solution? (answer)
23. How Kafka is used in a event driven architecture?
24. Is it possible to lose the message in Apache Kafka?
Yes, its possible but its rare and you should research more about when its possible and whether you can recover message or not.
25. Does Apache Kafka support JMS (Java Messaging Service?
Kafka does support JMS and it provides JMS clients. It currently support JMS 1.1 specification. However there are certain JMS concepts which do not map one to one with Kafka and or simply doesn't make sense like non-persistent messages
That's all about common Apache Kafka interview questions and answers for Java developers. While I have written this articles, keeping Java interviews in mind, the knowledge shared here is valuable to anyone who is using Apache Kafka as middleware or messaging broker.
A solid knowledge of Apache Kafka functionality, its architecture, and working goes a long way in making better design decisions and also troubleshooting and debugging any Kafka related issues in production.
Other Interview Questions Articles you may like to
explore
Thanks for reading this article so far. If you like these Apache Kafka
interview questions and answers then please share them with your friends
and colleagues. If you have any questions or feedback then please drop a
note.
P.S. - If you are new to the Apache Kafka world and want to learn Apache Kafka in depth then you can also check out the list of best free Apache Kafka online courses. These are some of the best online courses from Udemy, Coursera, Pluralsight, Educative and other places and completely free.
- Top 10 Spring Framework Interview Questions with Answers (see here)
- 20 Stack And Queue interview questions with answers (stack questions)
- 50+ Data Structure and Algorithms Problems from Interviews (questions)
- 10 Dynamic Programming interview questions (DP questions)
- 10 Hibernate Interview Questions for Java EE developers (see here)
- 25 Recursion based Interview Questions with answers (recursion questions)
- 20 Java Design Pattern Questions asked on Interviews (see here)
- 15 Node.JS Interview Questions with answers (nodejs questions)
- 100+ Coding Problems and a few tips to crack interview (problems)
- 35 Python Questions from Interviews with answers (python questions)
- 10 JDBC Interview Questions for Java Programmers (questions)
- 15 Java NIO and Networking Interview Questions with Answers (see here)
- 15 TensorFlow interview questions with answers (TensorFlow questions)
- 15 Data Structure and Algorithm Questions from Java Interviews (read here)
- 25 Angular Interview Questions with Answers (Angular questions)
- Top 10 Trick Java Interview Questions and Answers (see here)
- 25 Vuejs Interview Questions with Answers (vuejs questions)
- Top 40 Core Java Phone Interview Questions with Answers (list)
- 30 Reactjs interview questions with Answers (react questions)
P.S. - If you are new to the Apache Kafka world and want to learn Apache Kafka in depth then you can also check out the list of best free Apache Kafka online courses. These are some of the best online courses from Udemy, Coursera, Pluralsight, Educative and other places and completely free.












1 comment :
Can anyone please answer these Kafka questions for me?
Explain the producer & consumer-based architecture of Kafka.
How to configure the Kafka details?
What is offset in Kafka? If any consumer fails or crashed and then comes alive after some time, then can it continue consuming the messages?
How does Kafka handle this case? What is __consumer_offset?
How to determine the replication factor?
How to persist data directly from Kafka topic.is it possible or not?
Post a Comment