Hello guys, if you are using Microservice architecture and want to learn about different Microservice design patterns and principles to better architect your application then you have come to the right place. Earlier, I have shared the best Java Microservices courses and books for Java developers, and in this article, I am going to share the essential Microservice design principle and patterns. We will cover patterns like Event Sourcing, Circuit Breaker, SAGA, CQRS, Strangler, Database per Microservices, Backend for Frontend (BFF), Service Discovery, and API Gateway and principles like Scalability, Flexibility, Resiliency, etc. When you developing an enterprise application, it is good to move with micro-services rather than move with a monolithic architecture.
While there are cases where you would like to go with monolithic architecture like for low latency applications, but in most cases where you want to run your Java application in the cloud, Microservice architecture offers a better solution.
So let's have a quick look into what is microservices and it's use cases and design patterns for micro-services.
What is Microservice Architecture?
The microservice architecture is structured on the business domain and it's a collection of small autonomous services. In a microservice architecture, all the components are self-contained and wrap up around a single business capability.
Why do we need to consider the microservice architecture instead of using monolithic architecture? Below mentioned four main concepts that described the importance of microservice architecture over monolithic architecture.
1. Visibility is high - MSA provides better visibility to your services.
2.
Improves resilience - Improves the resilience of our service network
3.
Production time reduced - Reduce the delivery time from idea to final
product.
4. Reduced cost - Reduce the overall cost of designing,
implementing, and maintaining IT services.
If you are a complete beginner and want to learn more about Microservice architecture then I highly recommend you to go through these Microservice architecture courses to start with, in particular Grokking Microservices Design Patterns on DesignGuru.io, one of the best course to learn about Microservices patterns

10 Essential Microservice Design Patterns and Principles
Now that you know what is Microservice architecture and why you need to consider Microservice architecture to build applications that can stand the test of time and are scalable enough to handle real-world traffic, let's now go through the fundamental principle of Microservices and design pattern which you can use to solve common problem associate with microservice architecture.
Let's look at the principles in which the microservice architecture has been built.
1. Scalability
2. Flexibility
3. Independent and
autonomous
4. Decentralized governance
5. Resiliency
6.
Failure isolation.
7. Continuous delivery through the DevOps
while adhering to the above principles, there may have some other pitfalls that developers might befall and to avoid this, we can use the design patterns in a microservice architecture.
In this article, we are going to discuss 10 main design patterns which are mentioned below.
1. Database per Microservice
2. Event Sourcing
3. CQRS
4. Saga
5. BFF
6. API Gateway
7. Strangler
8. Circuit Breaker
9. Externalized Configuration
10. Consumer-Driven Contract Tracing
So first start with the Database per Microservice design pattern.

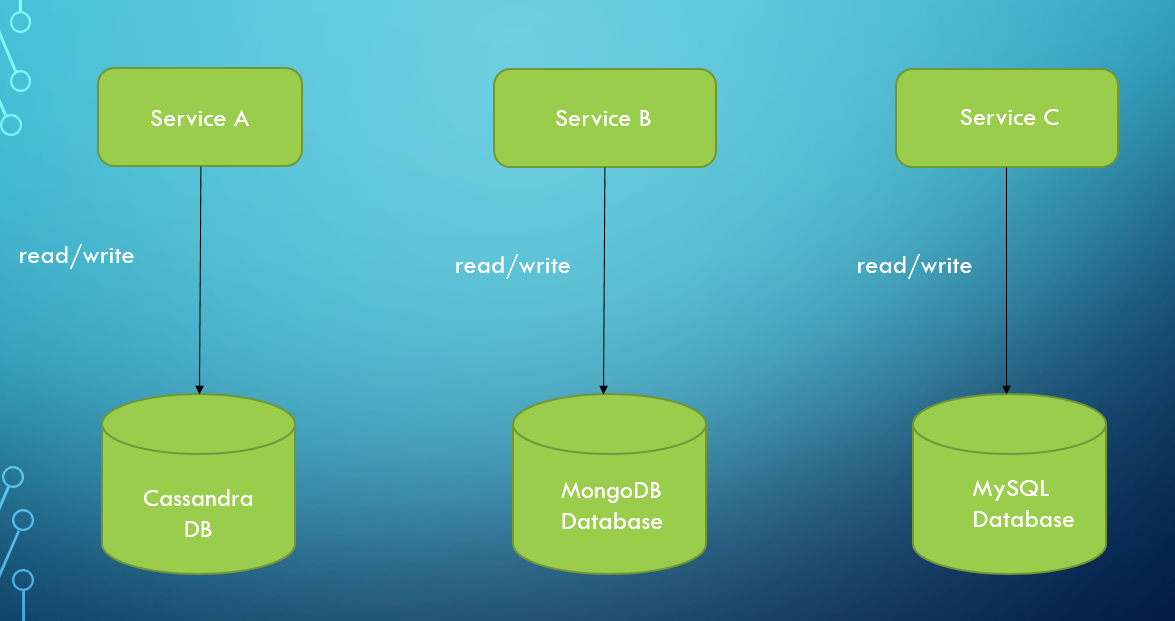
1. Database per Microservice Pattern
Database design is rapidly evolving, and there are numerous hurdles to overcome while developing a microservices-based solution. Database architecture is one of the most important aspects of microservices.
What is the best way to store data and where should it be stored?
There should are two main options for organizing the databases when using the microservice architecture.
- Database per service
- Shared database
1.1 Database per service.

2. Event Sourcing Pattern
- It's important to keep the existing data storage.
- There should be no changes to the existing data layer codebase.
- Transactions are critical to the application's success.

3. Command Query Segmentation (CQRS) Pattern

4. SAGA
In this choreography saga, there is no central orchestration. Each service in the Saga carries out its transaction and publishes events. The other services respond to those occurrences and carry out their tasks. In addition, depending on the scenario, they may or may not publish additional events.
In the Orchestration saga, each service participating in the saga performs their transactions and publish events. The other services respond to those events and complete their tasks.
Advantage of using SAGA
The disadvantage of using SAGA
5. Backend For Frontend (BFF)
Why BFF needs in our microservice application?
The goal of this architecture is to decouple the front-end apps from the
backend architecture.
As a scenario, think about you have an
application that consists of the mobile app, web app and needs to
communicate with the backend services in a microservices architecture.
This can be done successfully but if you want to make a change to one of the frontend services, you need to deploy a new version instead of stick to updating the one service.
Between the client and other external APIs, services, and so on, BFF functions similarly to a proxy server. If the request must pass through another component, the latency will undoubtedly increase.

6. API Gateway
- Use data from a previous request that has been cached.
- For time-sensitive data that is the request's major focus, return an error code.
- Provide an empty value
- Rely on hardware top 10 value.

7. Strangler

|
| Moving from Monolithic to microservice architecture stages. |
8. Circuit Breaker Pattern
The circuit breaker is the solution for the failure of remote calls or the hang without a response until some timeout limit is reached. You can run out of critical resources if you having many callers with an unresponsive supplier and this will lead to failure across the multiple systems in the applications.
So here comes the circuit breaker pattern which is wrapping up a protected function call in a circuit breaker object which monitors for failure.
When the number of failures reaches a specific level, the circuit breaker trips, and all subsequent calls to the circuit breaker result in an error or a different service or default message, rather than the protected call being made at all.
Different states in the circuit break pattern
Closed - When everything works well according to the normal way, the circuit breaker remains in this closed state.
Open - When the number of failures in the system exceeds the maximum threshold, this will lead to open up the open state. This will give the error for calls without executing the function.
Open -Half - After having run the system several times, the circuit breaker will go on to the half-open state in order to check the underlying problems are still exist.
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.bind.annotation.RequestMapping;
@RestController
@SpringBootApplication
public class StudentApplication {
@RequestMapping(value = "/student")
public String studentMethod(){
return "Calling the studentMethod";
}
public static void main(String[] args) {
SpringApplication.run(StudentApplication.class, args);
}
}
import java.net.URI;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
@Service
public class StudentService {
private final RestTemplate restTemplate;
public StudentService(RestTemplate rest) {
this.restTemplate = rest;
}
@HystrixCommand(fallbackMethod = "reliable")
public String studentMethodCalling() {
URI uri = URI.create("http://localhost:8000/student");
return this.restTemplate.getForObject(uri, String.class);
}
public String reliable() {
return "This is calling if the studentMethod is falling to respond on time";
}
}
So you can use the circuit breaker pattern to improve the fault tolerance and resilience of the microservice architecture and also prevent the cascading of failure to other microservices.
9. Externalized Configuration

@SpringBootApplication
@EnableConfigServer
@EnableDiscoveryClient
public class ConfigServerApplication {
}
Remove the application.properties file and create a new application.yml file with the following content.
server.port: 8001
spring:
application.name: config-server
cloud.config.server.git.uri: https://github.com/alejandro-du/vaadin-microservices-demo-config.giteureka:
client:
serviceUrl:
defaultZone: http://localhost:7001/eureka/
registryFetchIntervalSeconds: 1
instance:
leaseRenewalIntervalInSeconds: 1This sets the port (8001) and name (config-server) of the application, as well as the URI Spring Cloud Config should use to read the configuration from. On GitHub, we have a Git repository. The configuration files for all of the example application's microservices can be found in this repository. The admin-applicationmicroservic uses the admin-application.yml file, for example.
10. Consumer-Driven Contract Tracing
When a team is constructing multiple related services at the same time as part of a modernization effort, and your team knows the “domain language” of the bounded context but not the individual properties of each aggregate and event payload, the consumer driven contracts approach may be effective.It ensures that Microservices can interact with each other correctly by focusing on contracts or agreements between clients and service providers.In short, Consumer Driven Contract Tracing is an effective strategy for independent Microservice development and finding integration issues earlier.This microservice pattern is useful in legacy application which contains a large data model and existing service surface area. This design patterns will address the following issues,1. How can you add to an API without breaking downstream clients.2. How to find out who is using their service.3. How to make short release cycles with the continuous delivery.In an event driven architecture, many microservices expose two kinds of API's,1. RESTful API over HTTP2. HTTP and a message-based API The RESTful API allows for synchronous integration with these services as well as extensive querying capabilities for services that have received events from a service.

That's all about the top 10 Microservice Design patterns and principles. In this tutorial, we have also discussed what is microservice architecture and its most important design patterns. Microservice architecture and cloud computing go hand-in-hand because Microservice architecture makes development and deployment into the cloud easier.
Other Microservice and Java Resource articles you may like to explore
- Grokking Microservices Design Patterns Course
- 15 Microservice Interview Question and Answers
- Top 5 Courses to learn Microservice with Spring Boot
- 10 Free Courses to learn Spring for Beginners
- 5 Best Courses to learn Spring MVC for Beginners
- Difference between Microservices and Monolithic architecture
- 5 Online Courses to learn Core Java for Free
- 5 Essential Skills to Crack Coding Interviews
- 10 courses for Programming/Coding Job Interviews
- 5 Free Spring Framework Courses for Java Developers
- 10 Advanced Spring Boot Courses for Java Programmers
- Top 5 Java design patterns courses for experienced Java devs
- 5 Courses to Learn Big Data and Apache Spark
- 10 Best Courses to learn Spring in-depth
- 5 Essential Frameworks Every Java developer should learn
- 10 Free Spring Boot Tutorials and Courses for Java Devs
Thanks for reading this article so far. If you like these essential Microservice design patterns and principles then please share them with your friends and colleagues. If you have any questions, feedback, or other fee courses to add to this list, please feel free to suggest.












5 comments :
One good addition would be communication mechanisms between different microservices. One to one, one to many, synchronous and asynchronous.
The use of a shared database is an anti-pattern…. Doesn't make sense especially when your database is hosted in the cloud.
You missed Service Registry and Distributed Tracing
Yes, thanks for pointing that out, I am going to add them and few more patterns pretty soon on the list.
Which framework is better for development Microservices in Java, Spring boot + Spring Cloud, or Quarkus? Does any of these framework provide in-built support for these patterns?
Post a Comment