In the SQL Server database, there are mainly two types of indexes, Clustered index, and the Non-Clustered index and difference between Clustered and Non-Clustered index are very important from an SQL performance perspective. It is also one of the most common SQL Interview questions, similar to the difference between truncate and delete, primary key or unique key, or correlated vs non-correlated subquery. For those, who are not aware of the benefits of Index or why we use an index in the database, they help in making your SELECT query faster.
A query with an index is sometimes 100 times faster than a query without an index, of course depending upon how big your table is, but, you must index on columns that are frequently used in the WHERE clause of the SELECT query, or which forms a major criterion for searching in the database.
A query with an index is sometimes 100 times faster than a query without an index, of course depending upon how big your table is, but, you must index on columns that are frequently used in the WHERE clause of the SELECT query, or which forms a major criterion for searching in the database.
For example in the Employee database, EmployeeId or EmployeeName are common conditions to find an Employee in the database.
As I said, there can be either clustered index or non clustered index in the database, the former is used to decide how data is physically stored in disk and that's why there can be only one clustered index on any table.
In this article, we will explore more about both of these indexes and learn some key differences between clustered and non clustered indexes from the interview and performance perspective.
2 Types of Indexes in SQL
Continuing from the first paragraph, Indexes are used to make search faster in SQL. They are mostly maintained as a balanced tree (BST), where tree traversal gives you performance in the order of log(N). In case of the clustered index, data is present in leaf node, so when we run a particular query, which uses clustered index, we can directly find the data by tree traversal.
The Query optimizer is a component of the database, which decides whether to use an index or not to execute a SELECT query or if use index then which one. You can even see, which index is used for executing your query by looking at the query plan, a FULL TABLE SCAN means no index is used and every row of the table is scanned by the database to find data.
On the other hand INDEX UNIQUE SCAN or INDEX RANGE SCAN suggest use of Index for finding data. By the Index also has there own disadvantage as they make INSERT and UPDATE query slower and they also need space. A careful use of index is the best way to go.
The Query optimizer is a component of the database, which decides whether to use an index or not to execute a SELECT query or if use index then which one. You can even see, which index is used for executing your query by looking at the query plan, a FULL TABLE SCAN means no index is used and every row of the table is scanned by the database to find data.
On the other hand INDEX UNIQUE SCAN or INDEX RANGE SCAN suggest use of Index for finding data. By the Index also has there own disadvantage as they make INSERT and UPDATE query slower and they also need space. A careful use of index is the best way to go.
And if you like differences in tabular format, here is a nice table highlighting difference between clustered and non-clustered index in SQL
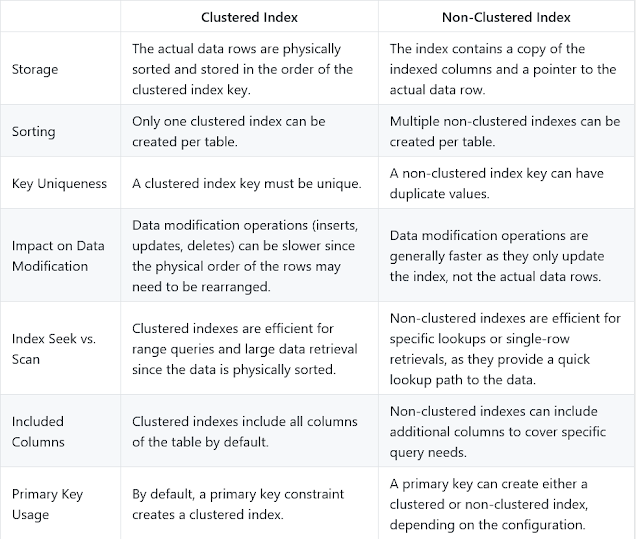
Clustered vs Non Clustered Index in SQL
Now we have some idea about what is Index in database and how they work, it's time to look some key differences between clustered and non clustered index in SQL Server, which is mostly true for other database as well e.g. Oracle or MySQL.
1) Limit per table
One of the main differences between clustered and non clustered index in SQL Server is that one table can only have one clustered Index but It can have many non clustered index, approximately 250. This limitation comes from the fact clustered index is used to determines how data is stored physically in the table.You should be very careful while choosing clustered index and should use columns which can be queried in range e.g. select * from Employee where EMP_ID > 20 and EMP_ID < 50. Since clustered index stores data in the cluster, related data are stored together and it's easy for the database to retrieve all data in one shot. This further reduces lots of disk IO which is a very expensive operation.
The Clustered Index is also very good on finding unique values in a table e.g. queries like select * from Employee where EMP_ID=40; can be very fast if EMP_ID has clustered index on it.
2) Primary Key
Another key difference between the Clustered Index and Non-Clustered Index in the database is that many relational databases including SQL Server by default creates clustered index on the PRIMARY KEY constraint, if there is no clustered index exists in database and a nonclustered index is not specified while declaring PRIMARY KEY constraint.3. Data vs Address
One more difference between them is that clustered index contains data i..e rows in their leaf node, as Index is represented as BST, while nonclustered index contains pointer to data (address or rows) in their leaf node, which means one more extra step to get the data. 4) By the way, there is a misconception that we can only define clustered index with one column, which is not true. You can create clustered index with multiple columns, known as the composite index.
4) By the way, there is a misconception that we can only define clustered index with one column, which is not true. You can create clustered index with multiple columns, known as the composite index. For example in Employee table, a composite index on firstname and lastname can be a good clustered index, because most of the query uses this as criterion. Though you should try to minimize the number of columns in the clustered index for better performance in SQL Server.
On a related note, while declaring composite index, pay some attention to the order of columns in the index, which can decide which statement will use index and which will not. In fact, this is one of the most asked questions as does the order of columns in composite index matter.
Last but not the least, pay some attention while creating clustered and non clustered indexes in the database. Create a clustered index for columns that contains unique values, are accessed sequentially, used in range queries and return a large result set. Avoid creating a clustered index on columns, which are updated frequently because that would lead to rearrangement of rows on disk level, a potentially slow operation.
That's all on the difference between clustered and nonclustered index in SQL Server database. Remember that, it's possible to create clustered index on non PRIMARY KEY column and PRIMARY KEY constraint only creates a clustered index, if there is not already in database and a nonclustered index is not provided. Key difference is that, clustered index decides physical sorting or order of data in disk.
3 comments :
When you say that in clustered indices, leaves of BST contain data, are those data whole records of a table, or just values of column(s) we've built clustered index on?
@Anonymous, SQL Server stores data in pages with size of 8KB. Leaf node actually contains these pages in case of clustered index, but in case of nonclustered index they contain address of these pages. Columns which are used to build indexes also known as key are stored in different data structure.
Thanks for the great article! Very helpful!
Post a Comment