Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from structured and unstructured data, and how to apply knowledge from data across a broad range of application domains.
20 Data Science Interview Questions with Answers
Without wasting anymore of your time, here is a list of common Data Science Interview questions and answers you can use to revise key Data Science concept before your interview. I have tried to include as many questions and concepts as possible but if you think a topic or two is missing then feel free to suggest in comments. You can also share Data Science questions asked to you during interviews.1. Explain the steps followed in making a decision tree
Answer:
- Take the entire data set as input.
- Calculate entropy of the target variable and also the predictor attributes.
- Calculate your information gain for all the attributes.
- Choose the attribute with the highest information gain as the root node.
- Repeat the same procedure on every branch until the decision node of each branch is finalized.
2. What are the differences between supervised and unsupervised learning?
Answer: Here are few difference between supervised and unsupervised learning in Machine Learning:
|
Supervised Learning |
Unsupervised Learning |
|
Uses a training data set |
Uses the input data set |
|
Input data is labelled |
Input data is unlabeled |
|
Enables classification and regression |
Enables classification, density estimation and dimension reduction |
|
Used for prediction |
Used for analysis |
Here is also a nice diagram which explains the difference between supervised and unsupervised learning :
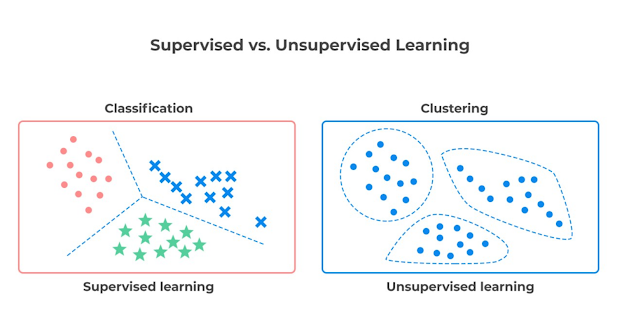
3. What is selection bias?
Answer:
Selection bias is a type of error that occurs when the researcher is
the one who decides who is going to be studied. It normally occurs where
the selection of participants is not random.
4. What are the types of selection bias?
Answer:
- Sampling bias
- Attrition
- Time interval
- Data
5. Why R is used in Data Visualization?
Answer:
R is used in data visualization because it has many inbuilt functions
and libraries which help in data visualizations. R plays a key role in
exploratory data analysis. It also helps in feature engineering.

6. What are the columns contained in order tables and customer tables?
Answer:
- Ordeid
- Order Table
- customerId
- TotalAmount
- Customer Table
- OrderNumber
- LastName
- City
- Country
- JOIN Customer
- FirstName
- Id
- FROM Order
- The SQL query is:
7. What are the differences between Data Science and Data Analytics?
Answer:
- Data Science is a broad technology that includes various subsets such as Data Analytics, Data Visualization and Data Mining while Data Analytics is a subset of Data Science.
- Data Science requires knowledge in advanced programming languages while Data Analytics requires only basic programming languages.
- A data scientist’s job is to provide insightful data visualizations from raw data that are easily understood while a data analyst’s job is to analyze data in order to make decisions.
- Data Science focuses on finding solutions and also predicting the future with past patterns while Data Analytics focuses only on finding solutions.
8. What are the popular libraries used in Data Science?
Answer:
- SciPy
- TensorFlow
- Pandas
- PyTorch
- Matplotib
9. What is variance in Data Science?
Answer:
Variance is a type of error that occurs in a Data Science model when
the model ends up being too complex and learns features from data, along
with the noise that exists in it.
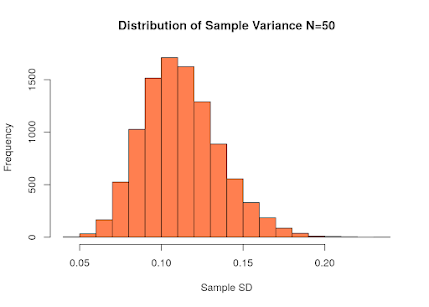
10. How do you build a random forest model?
Answer:
A random forest is built up of a number of decision trees. If you split
the data into different packages and make a decision tree in each of
the different groups of data, the random forest brings all those trees
together. Steps to build a random forest model are as follows:
- Randomly select 'k' features from a total of 'm' features where k << m
- Among the 'k' features, calculate the node D using the best split point
- Split the node into daughter nodes using the best split
- Repeat steps two and three until leaf nodes are finalized
- Build forest by repeating steps one to four for 'n' times to create 'n' number of trees
11. How can you avoid overfitting your model?
Answer:
Overfitting refers to a model that is only set for a very small amount
of data and ignores the bigger picture. There are three main methods to
avoid overfitting:
- Keep the model simple—take fewer variables into account, thereby removing some of the noise in the training data.
- Use cross-validation techniques, such as k folds cross-validation.
- Use regularization techniques, such as LASSO, that penalize certain model parameters if they're likely to cause overfitting.
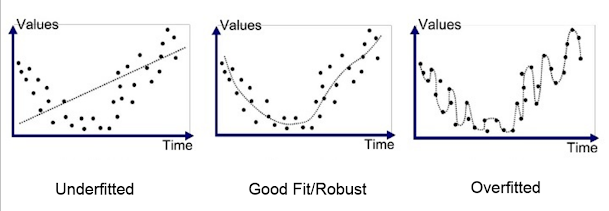
12. Why is resampling done?
Answer: Resampling is done in any of these cases:
- Estimating the accuracy of sample statistics by using subsets of accessible data, or drawing randomly with replacement from a set of data points
- Substituting labels on data points when performing significance tests
- Validating models by using random subsets (bootstrapping, cross-validation)
13. What does NLP stand for?
Answer:
NLP is the short form for Natural Language Processing. It deals with
the study of how computers learn a massive amount of textual data
through programming. A few popular examples of NLP are Stemming,
Sentimental Analysis, Tokenization, removal of stop words, etc.
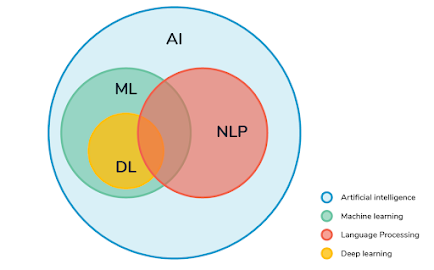
14. How to combat Overfitting and Underfitting?
Answer:
To combat overfitting and underfitting, you can resample the data to
estimate the model accuracy (k-fold cross-validation) and by having a
validation dataset to evaluate the model.
15. What Is the Law of Large Numbers?
Answer:
It is a theorem that describes the result of performing the same
experiment a large number of times. This theorem forms the basis of
frequency-style thinking. It says that the sample means, the sample
variance and the sample standard deviation converge to what they are
trying to estimate.
16. What is Survivorship Bias?
Answer:
It is the logical error of focusing aspects that support surviving some
process and casually overlooking those that did not work because of
their lack of prominence. This can lead to wrong conclusions in numerous
different means.

17. How data cleaning plays a vital role in the analysis?
Answer: Data cleaning can help in analysis because:
- Cleaning data from multiple sources helps to transform it into a format that data analysts or data scientists can work with.
- Data Cleaning helps to increase the accuracy of the model in machine learning.
- It is a cumbersome process because as the number of data sources increases, the time taken to clean the data increases exponentially due to the number of sources and the volume of data generated by these sources.
- It might take up to 80% of the time for just cleaning data making it a critical part of the analysis task.
18. What is dimensionality reduction?
Answer:
Dimensionality reduction is the process of converting a dataset with a
high number of dimensions (fields) to a dataset with a lower number of
dimensions. This is done by dropping some fields or columns from the
dataset. However, this is not done haphazardly. In this process, the
dimensions or fields are dropped only after making sure that the
remaining information will still be enough to succinctly describe
similar information.
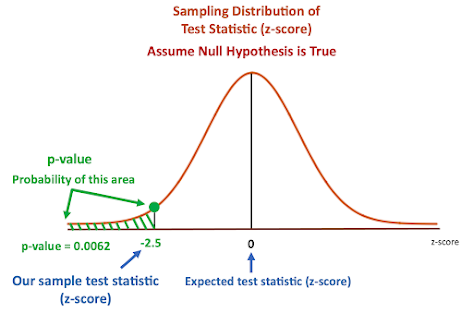
19. What is a p-value?
Answer:
P-value is the measure of the statistical importance of an observation.
It is the probability that shows the significance of output to the
data. We compute the p-value to know the test statistics of a model.
Typically, it helps us choose whether we can accept or reject the null
hypothesis.
20. How to detect if the time series data is stationary?
Answer:
Time series data is considered stationary when variance or mean is
constant with time. If the variance or mean does not change over a
period of time in the dataset, then we can draw the conclusion that, for
that period, the data is stationary.
That's all about 20 Data Science Interview Questions and Answers for practice. I believe you are now happy and smiling because you have had an easy time going through the questions with answers. You now have all it takes to pass your data science interview. Go for it without giving a second thought. You will surely excel and you will always thank yourself for taking your precious time to go through this article.
- Top 15 TensorFlow Interview Questions with Answers
- 35 Python Interview Questions for 1 to 2 years experienced
- 40+ Object-Oriented Programming Questions with Answers
- 130+ Java Interview Questions with Answers
- 20+ Spring Boot Interview Questions with Answers
- 20 Software Design and Pattern Questions from Interviews
- 10 Free Courses to learn SQL and Database
- 25+ Spring Security Interview Questions with Answers
- 20 Algorithms Interview Questions for Software Developers
- 10 Oracle Interview Questions with Answers
- 20 JUnit Interview Questions with Answers
- 17 Spring AOP Interview Questions with Answers
- 50 SQL and Database Interview Questions for Beginners
- 50+ Microsoft SQL Server Phone Interview questions
- Top 30 JavaScript Interview Questions for 1 year experienced
- Top 30 React.js Interview Questions for 2 years experienced
Thanks for reading this article so far. If you have any doubt or any questions or queries, you can drop them down in the comments and let someone else answer them; you can have a discussion too.












No comments :
Post a Comment